1. 시리즈 생성, 구조확인
- Pandas의 Series는 1차원 배열로서 인덱스(index) 사용 가능
- 문자 인덱스 사용 가능
- 데이터 타입 존재 (dtype)
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
#Series? # ndarray 기반의 일차원 배열이다.
ser = Series([1,2,3,4,5])
ser
'''
0 1
1 2
2 3
3 4
4 5
dtype: int64
'''
ser.shape # (5,)
ser = Series([1, '2', 3,0, '네 번째', 5]) # 데이터 타입 맞춰야 하지만 섞어서 입력
ser
'''
0 1
1 2
2 3
3 0
4 네 번째
5 5
dtype: object
'''
ndarray와 같이 series 역시 데이터 타입을 통일해야 하지만
series를 여러 데이터 타입을 섞어서 생성하면 가장 큰 데이터 타입인 str이 아닌 object 형태로 나옴
object가 나온다면 문자열이구나! 알아야 함. 정형 데이터에서는 object 타입이 없기 때문에!
ser = Series([1, '2', 3.0, '네 번째', 5]) # 데이터 타입 맞춰야 하지만 섞어서 입력
ser
'''
0 1
1 2
2 3
3 0
4 네 번째
5 5
dtype: object
'''
# 인덱싱 가능
print(ser[1]) # 2
print(ser[3]) # 네 번째
- .index ⇒ RangeIndex로 표기됨, 기본 부여된 index는 0~순차적으로 부여되기 때문
- RangeIndex는 Python list의 Index와는 다르게 -1과 같이 뒤에서 접근할 수 없음 ⇒ 모든 인덱스가 문자인 경우에만 사용 가능
Series 역시 ndarray 기반이기 때문에 index, values로 추출하면 값이 나온다!
ser1 = Series(np.random.randint(10,20,5)) # 10~20 사이의 5개
ser1
'''
0 13
1 19
2 13
3 13
4 11
dtype: int32
'''
# dataframe 은 인덱스가 있다!
# Series에도 있다!
print(ser1.index) # RangeIndex(start=0, stop=5, step=1)
# Series에도 Values가 있다
print(ser1.values) #[18 12 16 12 15]
print(ser1.dtype) # int32 요소들의 타입
- dtype을 지정한 경우 → numpy 기반이기 때문에 데이터형 확인 가능
- list로 생성한 경우
s = pd.Series([1,2,3,4,5], dtype='int')
s
'''
0 1
1 2
2 3
3 4
4 5
dtype: int32
'''
arr = np.arange(100, 105)
s = pd.Series(arr, dtype='float64')
s
'''
0 100.0
1 101.0
2 102.0
3 103.0
4 104.0
dtype: float64
'''
- index 지정 가능
# 인덱스를 명시적으로 지정할 수 있다.
# 5개 추출해서 abcde를 인덱스로 다섯 개 생성
ser1 = Series(np.random.randint(10,20,5), index=list('abcde'))
print(ser1[1]) # 13
print(ser1)
'''
a 12
b 14
c 11
d 12
e 15
dtype: int32
'''
print(ser1.index) # Index(['a', 'b', 'c', 'd', 'e'], dtype='object') => object인 걸 보니 문자열이 있구나!
print(ser1.values) #[[13 10 15 18 10]
print(ser1.dtype) # int32 요소들의 타입
ser1.dtypes # dtype('int32')
series의 shape은 series 데이터 크기와 같다 ⇒ 1차원 데이터이기 때문에 행렬 관계에서 행밖에 없음.. 행렬이 아님..!
ser.shape # (5,)
ser.size # 5
ser1.ndim # 1
- dtypes : column의 데이터형 확인
ser1.dtypes # dtype('int32')
슬라이싱을 숫자 인덱스말고 라벨링을 할 때는 end까지 포함됨
# 숫자로도 라벨로도 가능
ser1[0]
ser1['a']
'''
라벨 슬라이싱의 경우,
마지막 라벨이 포함된다!
'''
print(ser1[1:4]) # 1 <= a < 4
print(ser1['b':'d']) # 'b' <= a <='d'
# 숫자 인덱스와 문자 라벨링을 섞어 쓰면 에러
~~print(ser1[1:'d'])~~
'''
19
19
b 13
c 15
d 18
dtype: int32
b 13
c 15
d 18
dtype: int32
'''
print(ser1[:2])
'''
a 10
b 14
dtype: int32
'''
print(ser1[::2])
'''
a 10
c 14
e 18
dtype: int32
'''
# 선택한 index list로 인덱싱
i = ['a', 'c']
print(ser1[i])
'''
a 10
c 14
dtype: int32
'''
ser1_1 = ser1[::2]
print(ser1)
print(ser1_1)
'''
a 19
b 13
c 15
d 18
e 11
dtype: int32
a 19
c 15
e 11
dtype: int32
'''
2. 시리즈 값 조회하기
단일값을 선택하거나 여러값을 선택할때
1)인덱스로 라벨을 사용할수 있다.
2)슬라이싱 방법
- 라벨사용 : 마지막 라벨 포함됨 ['a' : 'd']
- 숫자사용 : 마지막 숫자 포함 안됨
# 5개 추출해서 abcde를 인덱스로 다섯 개 생성
ser1 = Series(np.random.randint(10,20,5), index=list('abcde'))
ser1
'''
a 19
b 13
c 15
d 18
e 11
dtype: int32
'''
ser1.dtypes #
dtype('int32')
# 숫자로도 라벨로도 가능
print(ser1[0]) # 19
print(ser1['a']) # 19
'''
라벨 슬라이싱의 경우,
마지막 라벨이 포함된다!
'''
print(ser1[1:4]) # 1 <= a < 4
print(ser1['b':'d']) # 'b' <= a <='d'
'''
b 13
c 15
d 18
dtype: int32
'''
print(ser1[:2])
'''
a 19
b 13
dtype: int32
'''
print(ser1[::2])
'''
a 19
c 15
e 11
dtype: int32
'''
ser1_1 = ser1[::2]
ser1_1
'''
a 19
c 15
e 11
dtype: int32
'''
print(ser1)
print(ser1_1)
'''
a 19
b 13
c 15
d 18
e 11
dtype: int32
a 19
c 15
e 11
dtype: int32
'''
- 시리즈 간의 연산
resSer = ser1+ser1_1
print(resSer)
'''
a 38.0
b NaN
c 30.0
d NaN
e 22.0
dtype: float64
'''
3. 누락 데이터 조회
- isnull() , isna() : Nan 값 찾는 함수
- notnull() , notna() : Nan이 아닌 값 찾는 함수
NaN 값 : pandas에서는 모든 결측치, 누락 데이터는 값이 없다 ⇒ NaN(Not a number), 숫자가 아니라는 의미가 아닌 None 값을 의미!!
int32형 ser1과 int32형 ser1_1을 더하기 연산했을 때 NaN의 영향으로 float형으로 dtype 출력
print(ser1)
print(ser1_1)
'''
a 19
b 13
c 15
d 18
e 11
dtype: int32
a 19
c 15
e 11
dtype: int32
'''
resSer = ser1+ser1_1
print(resSer)
'''
a 38.0
b NaN
c 30.0
d NaN
e 22.0
dtype: float64
'''
Nan 값 처리하는 과정
- Nan 값, 누락 데이터가 있는지 조회
- isnull(), isna() ⇒ 누락 데이터가 있는지 True, False 반환
- notnull() ⇒ 누락 데이터가 없는지
nan 값만 추출
# 1. 조건 찾아서
print(resSer.isnull())
print(resSer.isna())
'''
a False
b True
c False
d True
e False
dtype: bool
'''
# 2. 조건 값 처리
print(resSer[resSer.isnull()]) # True(nan 인 경우)를 추출해서 출력
'''
b NaN
d NaN
dtype: float64
'''
nan이 아닌 값만 추출
print(resSer.notnull())
'''
a True
b False
c True
d False
e True
dtype: bool
'''
print(resSer[resSer.notnull()])
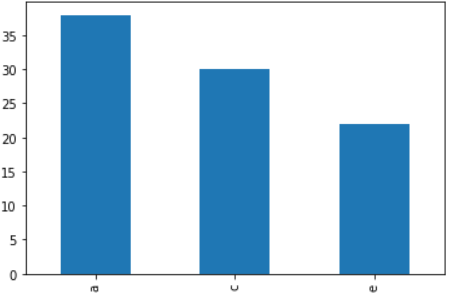
'''
a 38.0
c 30.0
e 22.0
dtype: float64
'''
nan 값의 개수 구하기 sum()
resSer.isnull().sum() # 2
- sum() 으로 누락 데이터 개수
- 컬럼별 누락 데이터 구하기
- 시각화
heap plot? 그래프 시각화, 누락 데이터가 나타나는 경우만 검은 바탕에 하얗게 표현
정보의 종류
- 필수 정보
- 선택 정보
누락 데이터는 존재하면 안 됨! 누락 데이터를 제거하여 머신 러닝 학습 진행 필수
함부로 데이터를 제거하면 안 되기 때문에 누락 데이터를 default를
- 0 이나
- 평균(mean) 값
- 100, 1, 2, 3, 4.. 데이터에서 100은 이상치 값으로 평균이 올바르지 않다. 따라서 이상치를 제거하여 중앙값(median)으로 default 설정
- 최빈값(자주 등장하는 값)으로 설정
Nan 값을 의도적으로 넣어주는 경우
np.nan
4. Pandas를 이용한 시각화
누락데이타가 아닌 데이타를 한눈에 보여준다
import matplotlib.pyplot as plt
resSer[resSer.notnull()].plot(kind='bar') #누락 데이터가 아닌 것만 시각화
plt.show()
'Python > 데이터 분석' 카테고리의 다른 글
| [DataFrame] DataFrame - 구조 확인 속성 (0) | 2022.04.02 |
|---|---|
| [DataFrame] DataFrame - 생성 (0) | 2022.04.02 |
| [pandas] pandas - Series, DataFrame (0) | 2022.04.02 |
| [Numpy] Numpy 배열의 통계함수 (0) | 2022.04.02 |
| [Numpy] Numpy 배열의 정렬 (0) | 2022.04.02 |




댓글