누락데이타 값 삭제하기 - dropna()
데이터를 보면 값이 없는 경우가 있다. 이런 경우 missing value 가 있다고 한다. 데이타 분석을 본격적으로 하기 전에 Missing value 처리 전략을 세우는 것은 데이타 전처리 과정에서 매우 중요하다. 데이타를 받으면 비어있는 값들이 어떻게 분포되어 있는지를 반드시 확인해야 한다.
대표적인 처리전략
- 데이터가 거의 없는 feature 는 feature 자체를 DROP
- 데이터의 최소 개수를 정해서 DROP
- 최빈값, 평균값, 0 등의 값으로 비어있는 데이터를 채우기 fill()
판다스는 누락된 데이타를 모두 NaN으로 처리한다.
판다스 객체의 모든 통계는 누락된 데이타를 배제하고 처리한다.
누락데이타와 관련된 기능
dropna() : na이 하나라도 있는 로우는 모두 DROP
dropna(how='all') :모든 값이 na인것만 DROP
dropna(how='any') : 누락 데이터가 한개라도 있으면 DROP 해라
fillna() :누락된 데이타 값을 다른 값으로 채움
isnull() or isna() : 누락되거나 NA인 값을 알려줌
notnull() :isnull()과 반대
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
tips =pd.read_csv('../dataset/tips.csv')
tips.head(1)
1. NaN 값 확인하기
'''
누락 데이터에 대한 전략을 세우기 앞서서
일단 누락 데이터가 얼마 정도 있는지 컬럼 확인부터 해보자
누락 데이터가 눈에 잘 안 들어온다.
isnull() 사용하자
'''
# 칼럼 확인과 함께 누락 데이터가 있는지 확인 가능
tips.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 245 entries, 0 to 244
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 245 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null object
3 smoker 244 non-null object
4 day 244 non-null object
5 time 244 non-null object
6 size 244 non-null float64
dtypes: float64(3), object(4)
memory usage: 13.5+ KB
'''
누락 데이터는 Ture로 표시됨. True로 표시된 것들은 값이 비어져 있다는 의미
tips.isnull()

# df.isnnull().sum()을 하면 각 칼럼별로 누락 데이터가 몇 개인지 바로 확인
# 이걸 가지고 확인하는 것이 가장 빠름!
tips.isnull().sum()
tips.isna().sum()
'''
total_bill 0
tip 1
sex 1
smoker 1
day 1
time 1
size 1
dtype: int64
'''
- 각 칼럼별 누락 데이터 :: tips.isnull().sum()
- 전체 데이터의 누락 데이터의 총 합 tips.isnull().sum().sum()
tips.isnull().sum().sum() # 6
'''
하다보면, 도대체 해당 데이터 프레임의 데이터가 어떻게 비워져 있는지 직접 확인
조건 필터링 사용하면 된다.
tip 의 누락 데이터가 어떻게 들어가 있는지 직접 확인
'''
condition = tips['tip'].isnull()
tips[condition] >> 사진 출력
tips.loc[condition, 'tip']
'''
244 NaN
Name: tip, dtype: float64
'''

2. NaN값 채우기
fillna(채울값) => 원본 훼손 안 됨

tc = tips.copy()
tc.tail()

# tip 칼럼에서 누락 데이터가 있으면 채우겠다
tc['tip'].fillna(99)
'''
0 1.01
1 1.66
2 3.50
3 3.31
4 3.61
...
240 2.00
241 2.00
242 1.75
243 3.00
244 99.00
Name: tip, Length: 245, dtype: float64
'''
tc.tail() # 원본 데이터 적용 안 됨
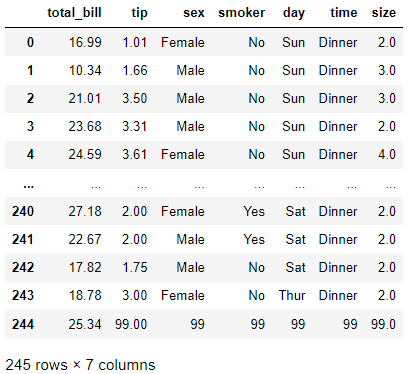
# inplace 속성으로 원본에 바로 적용
tc.fillna(99, inplace=True)
tc
fillna 는 위에서 살펴본 것처럼 재대입 방식과 inplace 옵션 사용하는 방식이 있는데
판다스 커뮤니티에서는 첫번째를 권장한다실수를 할수도 있기 때문이다.
한번 더 확인하고 넣어주는걸 더 선호한다.
✅ df4의 'temperature' 열의 결측치를 평균으로 채우세요.
mean =df4['temperature'].mean()
df4['temperature'].fillna(mean, inplace=True)
df4.loc[idx, :]
✅ df4의 'humidity' 열이 결측치인 행을 조회하세요
df4[df4['humidity'].isnull()]
3. NaN값 채우기
- 평균값으로 채우기 df[’age’].fillna(df[’age’].mean())
- 중앙값으로 채우기 df[’age’].fillna(df[’age’].median())
- 최빈값으로 채우기 df[’age’].fillna(df[’age’].mode()[0])
tc2 = tips.copy()
tc2.tail(1)
# tip 칼럼의 평균
mean = tc2['tip'].mean()
mean # 2.9982786885245902
# tip 칼럼의 누락 데이터를 위 평균 값으로 nan 값을 채운다.
tc2['tip'].fillna(tc2['tip'].median(), inplace=True) # 중앙값으로 채우기
tc2['tip'].fillna(tc2['tip'].mode()[0], inplace=True) # 최빈값으로 채우기
tc2['tip'].fillna(mean, inplace=True)
tc2.tail(1)

누락 데이터 값을 채울 때는 fillna()로 한 번에 채울 수 있다
# tip 칼럼의 평균
mean = tc2['tip'].mean()
mean # 2.9982786885245902
# tip 칼럼의 누락 데이터를 위 평균 값으로 nan 값을 채운다.
tc2['tip'].fillna(mean, inplace=True)
tc2.tail(1)

tc2['tip'].median() # 2.92
tc2['size'].mean() # 2.569672131147541
tc2['size'].median() # 2.0
4. NaN값 제거하기
특정 칼럼이나 열을 제거할 땐 drop()을 쓰지만 nan값을 제거할 때는 dropna를 사용한다 how 옵션을 무조건 사용하여
- dropna
- how 옵션
- any : 1개라도 NaN값이 존재하면 dropall : 모두 NaN값이 존재하면 dropthrash?? 몇 개 미만이면 drop
- 기본 옵션값은 how=any

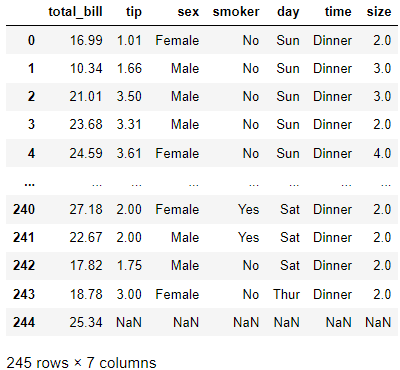
tc3 = tips.copy()
tc3.tail(1)
tc3.dropna()
# 여러 칼럼 중 하나의 행이라도 nan이 있으면 drop
# how='any' 가 디폴트
tc3.dropna(how='any')
tc3.tail(1) # 원본엔 적용 안 된 거 확인하기

tc3.dropna(how='all')
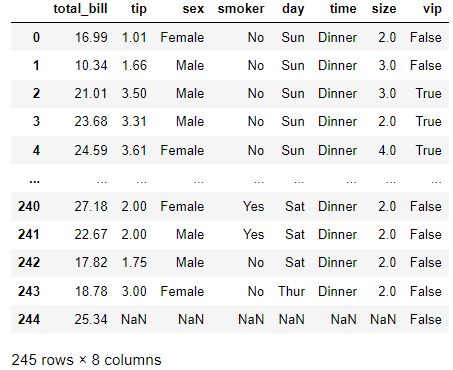
✅ 연습문제 1
아래 조건에 따라서 데이타를 처리합니다.
- Sun(일요일) 에 식사한 사람들
- 그리고 (and) total_bill 이 20달러 이상 지불한 사람vip 칼럼 생성1,2 만족하는 vip 고객이면 True,
- 1,2를 조건 필터링 한 후,
- vip열을 새롭게 만들어서 True, 그렇지 않은 사람들은 False로 입력합니다.
tc4 = tips.copy()
condition1 = tips['day']=='Sun'
condition2 = tips['total_bill'] >= 20
tc4['vip'] = condition1 & condition2
tc4
삭제는 행(row)삭제와 열(column)삭제로 구분한다
- 행삭제
- 특정한 index 지정해서 삭제index 범위를 지정해서 삭제
- 열삭제
- aixs=1 옵션을 반드시 지정다수의 컬럼도 삭제 가능
원본 적용 안 되기 때문에 inplace=False이다.
삭제된 내용을 바로 적용하려면 inplace옵션 True 지정해야 한다
데이터를 삭제하는 방법 drop열방향으로 삭제할 땐 반드시 axis=1, default가 0이기 때문!
행(row) 삭제하기
tc4.drop(0) # 0번 index 행방향 삭제 => axis=0이 default이다
tc4.head(1) # 첫 번째 행 출력해도 원본 훼손 안 되기 때문에 그대로 인덱스 0 남아있음
슬라이싱 방식으로 drop하기
# 슬라이싱 Error
# 인덱스 0은 놔두고, 1~5까지 drop 슬라이싱 안 됨
#tc4.drop[1:6]
tc4.drop(index=[1,2,3,4,5])
tc4.drop(labels=range(1,6))
# 가장 직관적인 방법
tc4.drop(tc4.index[1:6])
# Error
tips.drop(tips.iloc[1:4, :])
열(column) 삭제하기
axis=1 행 방향으로 삭제하기 위해 꼭 필요한 속성!!!!!
# 열 추가하기
tc4['age'] = 0
tc4.head()
#tc4.drop('vip') # KeyError: "['vip'] not found in axis" 행이 없어!
tc4.drop('vip', axis=1)
tc4
tc4.drop(['vip', 'age'], 1, inplace=True) # 칼럼명 리스트, axis 속성
tc4.head()
'Python > 데이터 분석' 카테고리의 다른 글
| [DataFrame] DataFrame - Grouping, pivot_table (0) | 2022.04.08 |
|---|---|
| [DataFrame] DataFrame - 통계 함수, 날짜 변수 (0) | 2022.04.08 |
| [DataFrame] DataFrame - 조회하기 (0) | 2022.04.08 |
| [DataFrame] DataFrame - 컬럼 다루기 & 컬럼명 변경 및 추가, 삭제하기 (0) | 2022.04.02 |
| [DataFrame] DataFrame - 정렬하기 (0) | 2022.04.02 |




댓글