머신 러닝(Machine Learning)
- 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
- 데이터로부터 모델을 자동으로 생성하여 스스로 성능을 향상하는 시스템으로 볼 수 있음
1️⃣Training DataSet
- Data, InputData, Feature, X
- Label, Target, 정답, y
2️⃣Machine(Model)
- 입력
- fit
- 데이터셋에 대한 패턴 분석 후 검증
3️⃣ Predict, 예측, 검증 데이터셋
학습에서 사용되지 않는 미지의 데이터들을 학습한 결과를 바탕으로 Model이 예측할 것임!
4️⃣ 정확한 예측 결과
미지의 데이터 셋의 실제 라벨과 예측된 라벨을 비교하여 정확도 판단!
예측 모델 : 데이터를 입력 받아서 모델에 학습하기
검증 모델 : test 데이터로 예측하기
▪️ 머신러닝 장점
- 인간이 예측하지 못 하는 복잡한 데이터 패턴을 학습으로 잡아낸다.
- 도메인 영역에 대한 지식이 상대적으로 부족해도 가능, 초반에는 반대로 문제였음!
▪️ 머신러닝 단점
- 데이터 의존성이 크다. 양질의 데이터가 많이 필요하다. (Garbage In, Garbage Out!)
- Data 편향(ImBalance Data)을 조심해야 한다.
- 쇼핑몰의 여성 데이터 80%, 남성 데이터 20%
- 개 이미지 100만장, 고양이 이미지 500장
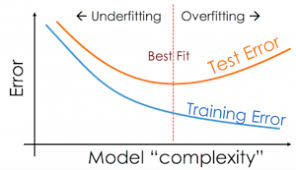
- 과대적합(Overfitting) 오류에 빠지기 쉽다. 특정한 데이터에만 민감하게 반응한다. 모델은 학습(training) 모델과 검증(test) 모델 두 가지로 나뉘는데 학습(training) 모델에서는 정확도 (accuracy)가 잘 나오는 반면, 검증(test) 모델에서는 정확도가 떨어진다.
- 과대적합(Overfitting) : 정보를 과도하게 학습해 일반화된 설명력이 떨어지는 상태
- 과소적합(Underfitting) : 정보를 충분히 학습하지 못해 설명력이 떨어지는 상태
과적합인지 아닌지 구분하는 방법
- 정확도가 100%이면 loss가 0인데 불가능한 것임! 학습 데이터를 외운 것이라 생각할 수 있음!
- 내가 학습한 데이터에서만 성능이 높게 나오고, 미지의 데이터가 들어오면 정확도가 떨어진다. 이 과적합 오류를 얼마나 줄이는지에 따라 성능 차이남
우리가 궁극적으로 데이터를 학습시키는 목적은 미지의 데이터를 넣었을 때 정확도가 100이어야 하는 것이다.
Training data의 에러율은 학습시킬 수록 줄어들지만 학습시킬 수록 training data에 적합해지기 때문에 Test data의 에러율은 줄어들다가 높아지는 경향이 있다.
- 데이터 입력 받고 학습 시킨다.
- Test model에서는 학습 안 하고 검증하는 데에만 사용한다.
용어정리
- 특성(Feature)
- X(이차원 데이터라서 대문자 X), Input Data(입력 데이터), 데이터, 속성, ... 으로 불림
- 통계에선 독립 변수로 많이 사용되며 머신 러닝 영역에선 특성(Feature)로 많이 사용
- 이외에도 설명 변수, 위험 인자라고도 함
- 레이블(Label)
- y(scalar 데이터라서 소문자 y), target, class, 정답, ... 으로 불림
- 통계에선 종속 변수로 많이 사용되며 머신 러닝 영역에선 레이블(Label), 클래스(Class)로 많이 사용
- 이외에도 응답 변수, 표적 변수, 결과 변수라고도 함
- 데이터 프레임의 한 컬럼이 특성 또는 레이블이 됨
- ex> 공부한 시간(X)에 따라서 성적(Y)이 결정된다.
scikit-learn 개요
- scikit-learn은 2007년 구글 썸머 코드에서 처음 구현됐으며 현재 파이썬으로 구현된 가장 유명한 기계 학습 오픈 소스 라이브러리
- 통일된 인터페이스를 가지고 있기 때문에 매우 간단하게 여러 기법을 적용할 수 있어 쉽고 빠르게 최상의 결과를 얻을 수 있음
- 라이브러리의 구성은 크게 지도 학습, 비지도 학습, 모델 선택 및 평가, 데이터 변환으로 나눌 수 있음
- 지도 학습에는 서포트 벡터 머신, 결정 트리(Decision Tree) 모델이 있음
- 비지도 학습에는 군집화, 이상치 검출 모델이 있음
- 모델 선택 및 평가에는 교차 검증(crooss-validation), 파이프라인(pipeline) 기능이 있음
- 데이터 변환에는 속성 추출(Feature Extraction), 전처리(Preprocessing) 기능이 있음
- 정제된 연습용 데이터 세트가 존재
- 공통적으로 사용되는 키
- data : X 데이터 (2차원 Numpy ndarray)
- target : Y 데이터 (1차원 Numpy ndarray)
- feature_names : X 데이터에 대한 정보(컬럼명)
- target_names : Y 데이터에 대한 정보(분류 데이터에만 존재)
- DESCR : 데이터 설명문(문자열)
⭐ scikit-learn 지도 학습
https://scikit-learn.org/stable/supervised_learning.html
1. Supervised learning
Linear Models- Ordinary Least Squares, Ridge regression and classification, Lasso, Multi-task Lasso, Elastic-Net, Multi-task Elastic-Net, Least Angle Regression, LARS Lasso, Orthogonal Matching Pur...
scikit-learn.org
최소 제곱법으로 만들어진 알고리즘 ⇒ Linear Regression
Logistic Regression ⇒ 분류 모델
Stochastic Gradient Descent - SGD ⇒ 많이 쓰임
Polynomial regression: extending linear models with basis functions ⇒ 과대적합을 낮추는 모델이 될 수 있음!
⭐ scikit-learn 비지도 학습
K-means
DBSCAN
auto ML
⭐ 모델 성능 확인용 데이터 셋 제공
https://scikit-learn.org/stable/datasets.html
7. Dataset loading utilities
The sklearn.datasets package embeds some small toy datasets as introduced in the Getting Started section. This package also features helpers to fetch larger datasets commonly used by the machine le...
scikit-learn.org
'AI > 머신러닝' 카테고리의 다른 글
| [머신러닝] 데이터 전처리 | 표준화, 정규화 (0) | 2022.04.12 |
|---|---|
| [머신러닝] K-최근접 이웃(K-NN) 분류 알고리즘 - 실습 (0) | 2022.04.11 |
| [머신러닝] K-최근접 이웃(K-NN) 분류 알고리즘 (0) | 2022.04.11 |
| [머신러닝] 데이터셋 다루기 (0) | 2022.04.11 |
| [머신러닝] 인공지능 개요 (0) | 2022.03.15 |




댓글