Colab
- Cloud 기반의 JupyterNB
- 무료 GPU 서버 제공
- 리눅스 기반
- CPU
Dual core(2개)
Quard core(4개)
core는 CPU 개수
- GPU
GPU로 학습할 때 이점?
속도가 빠르다 ⇒ core 개수가 다름!
core 2000개.. 500배 차이까지는 아니지만 병렬적으로 작업하기 때문에 연산량이 많을 때 속도가 빨라서 딥러닝의 경우 GPU로 학습하는 게 좋다.
Google Driver에 있는 Dataset은 Cloud 환경에 로드된 데이터셋
- Google Driver 임포트 from google.colab import drive
- mount ⇒ 구글 드라이브에 있는 데이터를 colab으로 mount 해줌경로 지정할 때 content는 colab의 local HOME이다. google driver가 colab에 올라타야 하기 때문에 content에 접근해야 한다. drive.mount( ‘/content/drive’ )
구글 드라이브 Data가 Colab으로 들어옴
colab의 local은 bin, boot, 등 굉장히 많은데 HOME이라고 부르는 폴더는 content이다.
content 아래에 drive라는 디렉토리가 있다.
drive 디렉토리는 Google Drive Data가 마운트 되는 위치
drive > myDrive 이 하위에 Google drive의 data가 로드되는 위치
Colab에는 파일을 일일이 올리면 시간 너무 오래 걸려서 zip 압축 파일로 업로드 해야 함
Pytorch에서의 Gradient Descent
파이토치를 이용해서 선형회귀를 위한 연산 그래프를 만들고 경사하강법을 이해하는 간단한 코드를 작성해 보겠습니다.파이토치에서는 데이타의 기본 단위로 텐서(Tensor)를 사용합니다. Numpy에서의 np.array()와 동일합니다.즉 텐서는 n차원의 배열을 전부 포함하는 넓은 개념이고 파이토치는 이러한 텐서를 기본 연산의 단위로 사용합니다.텐서를 생성하는 방법에는 여러가지가 있는데 가장 단순하게는 torch.Tensor() 를 이용합니다.
Torch Configuration
import torch
import torchvision # Image Processing에 특화된 모듈
import torch.nn as nn # Neural Net의 약자
import torchvision.transforms as transforms # Data Augmentation 관련 모듈
tensor 사용하기
x = torch.tensor(data = [2.0, 3.0], requires_grad=True) # 미분 사용하겠다
y = x**2 # y 값은 x의 자승으로 4, 9
# 예측값 11, 21
pred = 2 * y + 3 # x는 y값으로 bias는 3
target = torch.tensor(data = [3.0, 4.0])
# 예측 잘했는지 정량화 loss 구하기
loss = torch.sum(torch.abs(pred-target)) # 예측값에서 target을 뺀 값의 절댓값
print('Loss', loss) # Loss tensor(25., grad_fn=<SumBackward0>)
Create Tensor, NN Generator
x = torch.randn(10,3) # 10행 3열 랜덤 수
y = torch.randn(10,2) # 10행 2열의 랜덤 수
print(x, y)
'''
tensor([[-0.8621, 0.7446, 1.8334],
[ 0.5669, -0.6268, -0.4157],
[ 0.3710, -0.3539, -1.1113],
[-0.8698, -2.3090, -0.6179],
[-0.4300, 2.3866, -0.3516],
[-0.5040, -0.2157, 0.8919],
[-0.0129, 0.7374, 0.4636],
[ 1.0984, -0.3159, 0.8987],
[ 1.2069, 0.3893, -0.6658],
[-0.9149, -1.0487, 0.7098]]) tensor([[ 0.8406, -0.0340],
[-0.7406, 0.6113],
[-1.5940, 0.3899],
[ 0.6218, -1.3161],
[-0.1041, 0.8800],
[ 0.0838, 0.6953],
[-0.0701, -0.2547],
[-0.1378, 0.5346],
[ 0.9017, -0.9023],
[-0.5551, 0.4702]])
'''
모델 생성
linear = nn.Linear(3,2) # 입력 값이 10,3이고 출력이 10,2니까 3,2
print('w',linear.weight)
'''
w Parameter containing:
tensor([[ 0.0929, -0.4755, 0.0427],
[ 0.1320, 0.4959, -0.0827]], requires_grad=True)
'''
print('b',linear.bias)
'''
b Parameter containing:
tensor([-0.1783, 0.3687], requires_grad=True)
'''
3행 2열로 만들어야 하는데 왜 2행 3열로 나왔을까? transpose 시켰기 때문에!
bias는 왜 1행 2열로 나왔나? 원래 y 행렬 형태와 같게 10행 2열이어야 한다. bias는 각 열마다 같은 값으로 더해지기 때문에 굳이 10행 출력 안 해줘도 된다!
Loss Function 선정의
loss_func = nn.MSELoss()
Optimizer 정의
.parameters() weight, bias 값을(학습/하산의 주체) 내포하고 있는 해킹된 함수
linear.parameters() # <generator object Module.parameters at 0x7ff2e40b7350>
예측 --> loss --> backward --> step
forward
- 모델 정의
- loss function 정의
- optimization
⇒ 모델에 값 집어넣기
backward
실직적으로 학습이 진행된다. 그 이유는 예측값을 가지고 얼마나 예측을 잘했는지 target인 y와 비교한 후 loss(고도=현재 위치)가 나오면 이 loss를 가지고 backpropagation을 진행한다.
backpropagation은 이 모델의 Loss가 나오는 데에 있어서 Weight과 bias가 어느 정도의 책임이 있는지 계산한다. 따라서 수정된 Weight과 bias 값으로 다시 Linear 연산이 이루어지며 loss를 줄여가며 0에 가깝게 만드는 과정을 반복한다.
pred = linear(x) # 모델에 값을 넣어주기, Wx+b의 결과로 예측값 뱉어냄! => 이것을 확률값으로 바꿔주는 softmax(exponential)
loss = loss_func(pred, y) # 위에서 나온 예측값과 미리 가지고 있던 값
print('loss before step Backpropagation ', loss.item()) # 1.9522184133529663 현재 고도
# Backpropagation
loss.backward() # loss에 대한 모든 weight와 bias에 대한 책임을 물어라!
# 학습의 주체들
print('dL/dW', linear.weight.grad) # 미분한 값
print('bias', linear.bias.grad)
'''
loss before step Backpropagation 0.7499625086784363
dL/dW tensor([[ 0.0842, -0.7286, -0.3072],
[ 0.1358, 0.3511, -0.1330]])
bias tensor([-0.0701, 0.2128])
'''
# 보정된 값으로 학습 진행 // 실질적인 학습 진행되는 부분임! 얼마나 예측을 잘 했는지(loss)
# 한 번만 낮춰서 loss 를 낮춘 것이지만 나중엔 반복적인 과정으로 loss 최대로 줄여야 함!
optimizer.step()
반복작업
pred = linear(x)
loss = loss_func(pred, y)
print('loss after step Backpropagation ', loss.item()) # 0.7415996789932251 변화된 고도
첫 번째 loss 값이 가장 높은 이유? 랜덤하게 주어지니까!
# **Torch Configuration**
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# **Hyper-parameters**
input_size = 1 # 1차원
output_size = 1 # 1차원
num_epochs = 100 # 학습 횟수 100번(default) 1 epoch마다 값
learning_rate = 0.001
# Toy Dataset
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
x_train
y_train
'''
(array([[ 3.3 ],
[ 4.4 ],
[ 5.5 ],
[ 6.71 ],
[ 6.93 ],
[ 4.168],
[ 9.779],
[ 6.182],
[ 7.59 ],
[ 2.167],
[ 7.042],
[10.791],
[ 5.313],
[ 7.997],
[ 3.1 ]], dtype=float32), array([[1.7 ],
[2.76 ],
[2.09 ],
[3.19 ],
[1.694],
[1.573],
[3.366],
[2.596],
[2.53 ],
[1.221],
[2.827],
[3.465],
[1.65 ],
[2.904],
[1.3 ]], dtype=float32))
'''
# Linear regression model
model = nn.Linear(input_size, output_size)
# Loss and Optimizer
# loss function 정의
loss_func = nn.MSELoss()
# optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Train the model
for epoch in range(num_epochs): # 100번 돌아감
# numpy 값을 tensor로 변경한 후 모델에 입력해야 한다.
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
# Forwards.. 진행방향 입력값 넣고, 예측값 출력되면 loss 값 나옴
preds = model(inputs) # 예측값은 모델에 입력 넣어서 만듦
loss = loss_func(preds, targets) # 모든 값들에 대한 loss가 각각 나오고 이 loss들의 평균을 구함 => loss는 모델 전체의 loss
# loss가 나왔으면 Weight에 대한 책임을 묻는 Backward 방향으로 진행
# 백워드 하기 전에 optimizer를 초기화 해줘야 함
optimizer.zero_grad()
# loss 값에 대한 편미분으로 책임 묻기
loss.backward()
optimizer.step() # 이때 비로소 학습이 진행된다.
if(epoch+1) % 5 == 0: # 5번씩 끊어서 출력
print('Epoch[{}/{}], Loss:{:.4f}'.format(epoch+1, num_epochs, loss.item())) # item() 함수로 tensor 내부 값 뽑기
# 첫 번째 weight와 bias 값이 랜덤하게 주어지기 때문에 가장 에러율이 높다
'''
Epoch[5/100], Loss:4.7592
Epoch[10/100], Loss:2.0686
Epoch[15/100], Loss:0.9785
Epoch[20/100], Loss:0.5368
Epoch[25/100], Loss:0.3577
Epoch[30/100], Loss:0.2851
Epoch[35/100], Loss:0.2556
Epoch[40/100], Loss:0.2435
Epoch[45/100], Loss:0.2385
Epoch[50/100], Loss:0.2364
Epoch[55/100], Loss:0.2354
Epoch[60/100], Loss:0.2350
Epoch[65/100], Loss:0.2347
Epoch[70/100], Loss:0.2344
Epoch[75/100], Loss:0.2342
Epoch[80/100], Loss:0.2341
Epoch[85/100], Loss:0.2339
Epoch[90/100], Loss:0.2337
Epoch[95/100], Loss:0.2336
Epoch[100/100], Loss:0.2334
'''
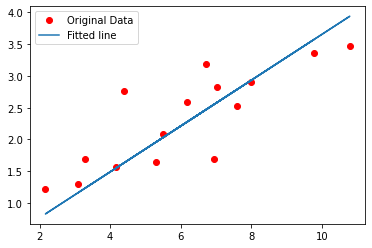
# Plot the graph
#detach 연산기록으로부터 분리시켜야 한다.
predicted = model(torch.from_numpy(x_train)).detach().numpy()
plt.plot(x_train, y_train, 'ro', label='Original Data')
plt.plot(x_train, predicted, label='Fitted line')
plt.legend()
plt.show()
torch.save(model.state_dict(), 'model.ckpt') # checkpoint
'AI > 딥러닝' 카테고리의 다른 글
| [딥러닝] Neural Network (0) | 2022.04.26 |
|---|---|
| [딥러닝] Backpropagation (0) | 2022.04.24 |
| [딥러닝] Computer vision, Classification, Linear Classifier, Loss Function (0) | 2022.04.24 |



댓글