Concat, Merge
서로 다른 데이타프레임을 하나로 합치는 작업
1) Concatenate
행 방향으로 연결됨
기본값이 axis=0 지정
이 경우에는 두 DataFrame이 서로 동일한 인덱스,컬럼을 가지고 있는 경우가 대부분
위+아래로 연결되는 방식이 기본이지만 좌,우로도 연결 가능하다.
outer join이 기본방식이다. <- Merge 방식, 합집합
key를 이용한 concat도 가능하다.
2) Merge => sql에서 join과 같음
두개의 DataFrame에 공통적으로 포함되어 있는 하나의 컬럼을 기준으로 합치는 방식
즉, 서로 다른 구성의 DataFrame이지만 공통된 key(컬럼)값을 가지고 있다면 병합 가능하다.
inner join이 기본방식. => 교집합
on 속성뒤 공통의 컬럼명
how 속성뒤 조인기법을 적용함
concat은 동일한 데이터의 날짜가 다르다던지, 분기별로 나뉜 것을 합치지만
merge는 서로 다른 데이터를 합칠 때 사용
Data Loader
2019년도 서울시 상반기, 하반기 주유소 데이터
gas1 = pd.read_csv('../dataset/gas_first_2019.csv', encoding='euc-kr')
gas2 = pd.read_csv('../dataset/gas_last_2019.csv', encoding='euc-kr')
데이터를 병합하는 방식 2가지
- concat 데이터를 상 하로 연결
- merge 데이터를 좌 우로 연결
concat으로도 좌우 연결할 수 있다 axis 축을 설정하자!
concat은 아래처럼 100줄짜리 A, 100줄짜리 B를 더하면 200줄이 된다.
즉, 아래로 붙일 땐 칼럼이 같을 때 사용한다.
A 데이터+B 데이터
gas1과 gas2는 상반기, 하반기 데이터이므로 아래로 이어서 붙이면 된다.
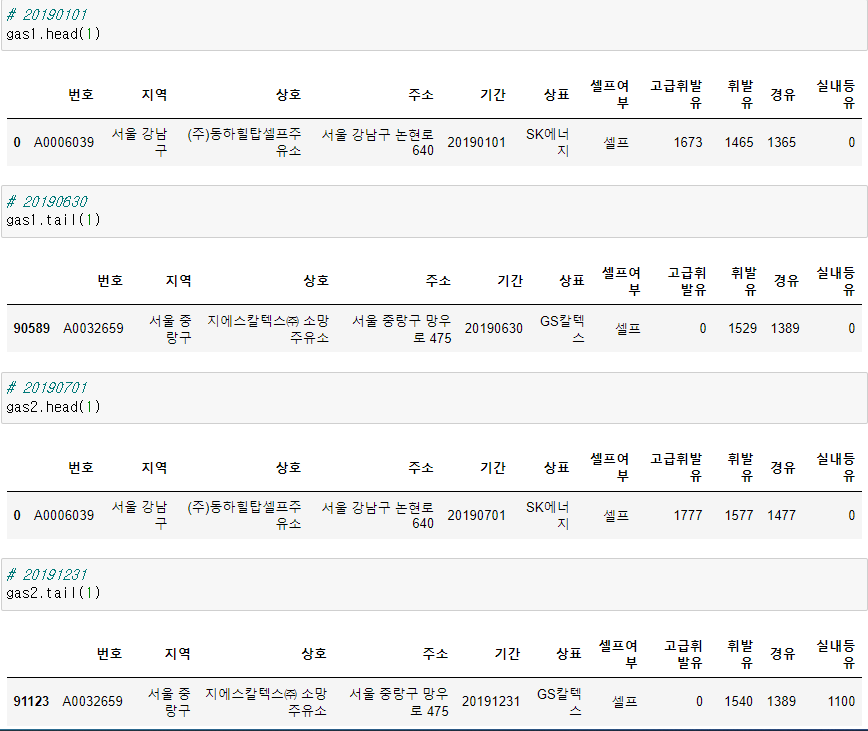
1. Concat
행 방향으로 합치기
# 리스트 형식 아니면 에러남
# 상반기 하반기 이어버렷!
pd.concat([gas1, gas2])
# 두 데이터를 더하면 181714개의 데이터가 출력되어야 하는데
# 인덱스가 아직 초기화되지 않아서 마지막 데이터의 인덱스가 91123이다.
# 따라서 concat()을 사용하여 데이터를 연결할 땐 인덱스 속성을 지정해줘야 한다


- concat 병합할 때는 keys 옵션을 사용하여 카테고리컬 혹은 범주는 넣을 수 있다!!
pd.concat([gas1, gas2], keys=['상반기', '하반기'])

- 병합한 데이타를 gas에 입력
gas = pd.concat([gas1, gas2])
# 상반기의 마지막 데이터, 하반기의 첫 데이터
gas.iloc[90588:90593]

index 리셋
'''
문제점
1. 인덱스는 잘 초기화 되어 지지만, 인덱스 컬럼이 중복 되어서 나온다.
drop() 하면서 동시에 인덱스를 초기화 해줘야 한다.
2. 원본 적용 안 된다.
(1) 재대입
(2) inplace=True
'''
# index가 리셋되어 정렬됨
gas.reset_index()
gas.head()

# 1. 과 2.를 한 번에 해결
gas = gas.reset_index(drop=True) # 인덱스가 생성되는 동시에 버려서 중복되지 않음
gas.head()
열 방향으로 합치기
gas1 = gas.iloc[:,:4]
gas2 = gas.iloc[:,4:] # 끊겼던 부분부터 끝가지
# 상 하 로 연결
pd.concat([gas1, gas2], axis=1).head()

2. Merge
- 기본적으로 inner 방식으로 합쳐진다 (how='inner')left_on, right_on
상호간에 없는 데이타는 제외시키고서로 있는 데이타만 합쳐준다(inner방식 == 교집합).
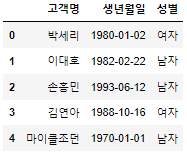
df1 = pd.DataFrame({
'고객명':['박세리','이대호','손흥민','김연아', '마이클조던'],
'생년월일':['1980-01-02','1982-02-22','1993-06-12','1988-10-16','1970-01-01'],
'성별':['여자', '남자','남자','여자','남자']
})
df1

df2= pd.DataFrame({
'고객명':['김연아','박세리','손흥민','이대호','타이거우즈'],
'연봉':['2000원','3000원','1500원','2500원','3500원']
})
df2

'''
서로 상이한 데이터프레임에서
고객명이라는 공통의 컬럼을 중심으로
두 데이터프레임 집단을 병합.. merge
df1이라는 데이터프레임에서 df2 데이터프레임의
연봉정보를 가져오고 싶다..
'''
# 리스트 형식으로 넣으면 안 됨
#공통적인 부분만 df1 + df2 뽑아서 공통적인 부부닝 없는
#df1에선 마이클 조던이 빠지고, df2에선 타이거 우즈가 빠짐
pd.merge(df1, df2)
#pd.merge?
how 옵션 4가지
- inner (default) 교집합
- reft
- right
- outer => concat

# outer 조인처럼 없는 값은 Nan으로 나옴
pd.merge(df1, df2, how='outer')

pd.merge(df1, df2, how='left')

pd.merge(df1, df2, how='right')
Q. contcat / merge(how 방식 네 가지)실무에서 merge의 네 가지 방식 중 가장 많이 사용하는 것?
A. left방식을 많이 씀 // inner가 default이긴 함!
본질적으로 동일한 컬럼명 일치시키기
# 이름과 고객명을 같은 칼럼이라 설정
pd.merge(df1, df2, left_on='이름', right_on='고객명')
# 공통적인 타이틀을 가져왔지만 공통적인 부분이기 때문에 칼럼 하나를 drop하자
pd.merge(df1, df2, left_on='이름', right_on='고객명').drop('고객명', axis=1)


'Python > 데이터 분석' 카테고리의 다른 글
| [Matplotlib] Matplot을 이용한 시각화 (0) | 2022.04.09 |
|---|---|
| [Pandas] Pandas - plot (0) | 2022.04.09 |
| [DataFrame] DataFrame - Grouping, pivot_table (0) | 2022.04.08 |
| [DataFrame] DataFrame - 통계 함수, 날짜 변수 (0) | 2022.04.08 |
| [DataFrame] DataFrame - 누락데이터 처리하기, 삭제하기 (0) | 2022.04.08 |




댓글