
plot
kind 옵션을 어떻게 지정하느냐에 따라서 다양한 그래프를 그릴수 있다.시각화 목적에 맞게 kind를 잘 지정해줘서 그린다
- line 선그래프
- bar 바그래프
- barh 수평 바그래프
- pie 파이그래프
- box 박스플롯
- kde 커널 밀도 그래프
- hist 히스토그램
- scatter 산점도 그래프
- area 면적 그래프

df['분양가격'].plot()

# 서울지역에 대한 집값만 보겠다.
df_s = df.loc[df['지역명']=='서울']
df_s

# 서울지역 연도별 분양가
df_s_year = df_s.groupby('연도').mean()
df_s_year

df_s_year['분양가격'].plot(kind='line')
# 그려줘
plt.show()
# 지역별 분양가
df.groupby('지역명')['분양가격'].mean()
'''
지역명
강원 2339.807547
경기 4072.667925
경남 2761.275472
경북 2432.128302
광주 2450.728302
대구 3538.920755
대전 2479.135849
부산 3679.920755
서울 7225.762264
세종 2815.098113
울산 1826.101887
인천 3578.433962
전남 2270.177358
전북 2322.060377
제주 2979.407547
충남 2388.324528
충북 2316.871698
Name: 분양가격, dtype: float64
'''

# 지역별 분양가
df.groupby('지역명')['분양가격'].mean().plot(kind='bar')
plt.show()

# bar를 barh로 변경하면 수평 그래프로 출력
# 분양 가격 순으로 정렬
df.groupby('지역명')['분양가격'].mean().sort_values().plot(kind='barh')
plt.show()
히스토그램(hist)
값의 분포
히스토그램은 분양가의 분포, 빈도를 시각화하여 보여준다가로축에는 분포율, 세로축에는 빈도가 시각화 되어진다

# 분양가의 분포를 보여준다
df['분양가격'].plot(kind='hist')
커널밀도 그래프 KDE
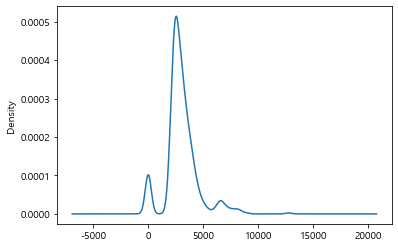
- 히스토그램과 유사하게 밀도를 보여주는 그래프
- 히스토그램과 유사한 모양을 갖추고 있다
- 부드러운 라인을 가지고 있다
- 히스토그램과 kde를 얹어서 결합해서 사용하기도 함
df['분양가격'].plot(kind='kde')
hexbin

일명 벌집피자
- hexbin은 고밀도 산점도 그래프
- x, y값 입력 필요
- x, y값은 모두 Numeric한 값을 입력해야 함
- 데이타의 밀도를 추정
df.plot(kind='hexbin', x='분양가격', y='연도', gridsize=24)
Boxplot

데이타 분석가들이 가장 많이 사용하는 그래프
중앙값을 기준으로 25%, 25%로 나뉨
중앙값에 1.5를 곱하면 IQR값이 됨
하단수염, 상단수염까지 100가지 데이터 나옴
보통 중앙값을 기준으로 50% 안에 들어있는 정도 =>1st~3rd까지의 내용물
이상치 값이 많을 땐 median 위치가 달라짐
possible outliers 이상치를 칼럼에서 추출하고 찾아내어 처리함

# 서울 지역에 대한 데이터프레임 추출
df_s=df.loc[df['지역명']=='서울']
# 서울 지역의 분양가격 boxplot 이상치 값이 눈에 띄게 많다. 상단에 동그라미들!
df_s['분양가격'].plot(kind='box')

# y축 눈금만들기, 평당 가격 잘게 쪼개기
plt.yticks([5000,6000,7000,8000,9000,10000,11000,12000,13000,14000,150000]) #=> 중앙값이 7000안되고, 이상치는 13000, 14000 확인 가능
df_s['분양가격'].plot(kind='box', grid=True)
Pie 그래프

얼마만큼의 점유율을 가지는가를 볼수 있다
df.groupby(by='연도')['분양가격'].count().plot(kind='pie')
scatter plot(산점도 그래프)

- 점으로 데이타를 표기
- x,y값이 필요함
- x,y축을 지정해주면 그에 맞는 데이타를 볼 수 있음
- Numeric한 컬럼에만 지정할수 있다.
df.groupby(by=['지역명','연도','월'])[['분양가격']].mean().sort_values(by=['연도','월','분양가격'])

# numeric한 데이터를 확실하게 알 수는 없었지만 이상치 확인 가능
df.plot(kind='scatter', x='월', y='분양가격')

# 위에서 이상치 확인 가능했으니 이상치를 확연하게 볼 수 있는 boxplot을 적용해보자.
df.plot(kind='box', x='월', y='분양가격')
'Python > 데이터 분석' 카테고리의 다른 글
| [Seaborn] Seaborn을 이용한 시각화 (0) | 2022.04.09 |
|---|---|
| [Matplotlib] Matplot을 이용한 시각화 (0) | 2022.04.09 |
| [Dataframe] Dataframe - 데이터 병합 (0) | 2022.04.09 |
| [DataFrame] DataFrame - Grouping, pivot_table (0) | 2022.04.08 |
| [DataFrame] DataFrame - 통계 함수, 날짜 변수 (0) | 2022.04.08 |




댓글