Seaborn
- Matplotlib를 기반으로 만들어진 파이썬 라이브러리
- Matplotlib을 더 사용하기 쉽게 만들어진 강력한 라이브러리
- 통계함수를 공학도들이 통계원리를 포함시켜 만듦
- 공식 사이트 http://seaborn.pydata.org
seaborn과 matplot과 다른 점?
내가 분석한 그래프를 시각화할 때 내가 색감을 지정해서 디자인을 구성하는 능력 중요!
seaborn에서 지정하는 palette 를 사용할 건데 어떤 그래프를 골라서 사용하는지도 중요하지만 color 선택이 정말 중요하다.
통계와 알고리즘을 절묘하게 섞어서 API를 만들어내어야 하는데 color는 미국 뉴욕의 현역 디자이너들, 전문가와 협력하여 만든 것이다.
Seaborn에서만 제공되는 통계기반 plot
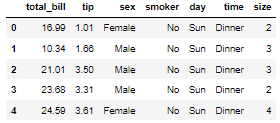
# seaborn을 import 하는 순간 데이터셋 할당 가능
tips = sns.load_dataset('tips')
tips.head()
1. violinplot
바이올린처럼 생겼다고 해서 붙여진 이름 그래프의 x, y 범위와 그에 따른 분포도를 함께 보여줌
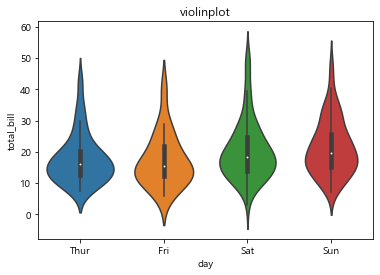
- 그래프 중간에 툭 튀어져 나온 부분을 주의깊게 살펴야 하고
- 위, 아래 양 끝쪽 데이터의 분포도 눈여겨 봐야한다
생각보다 목요일에 사람들이 많이 온다.
토요일과 일요일의 total_bill이 높다.
# 요일별 얼마나 비싼 음식을 먹었는지 궁금하다
sns.violinplot(x='day', y='total_bill', data=tips)
plt.title('violinplot')
plt.show()
hue 옵션 ⇒ 갈라치기
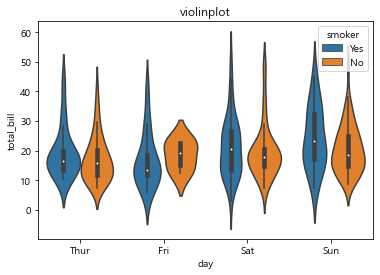
hue 옵션을 지정하면 알아서 legend가 생성됨
목요일에 흡연자가 가장 저렴한 음식을 먹었을 뿐만 아니라 편차가 크다
주말에 흡연/비흡연자 모두 평일보다 금액을 많이 지불하지만 흡연자가 더 많이 지불한다는 디테일한 정보 얻을 수 있다.
# hue 옵션 => 갈라치기,, 흡연 / 비흡연 비율로 나누어
sns.violinplot(x='day', y='total_bill', data=tips, hue='smoker')
plt.title('violinplot')
plt.show()
하지만 여러 개의 그래프로 비교하기 힘들 수 있다. ⇒ split 옵션을 지정해서
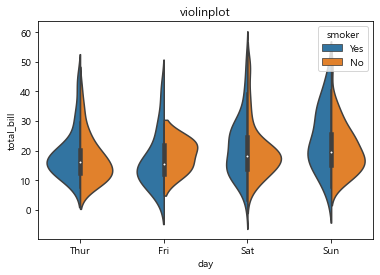
hue를 줬을 때 찢어지는 것을 하나로 합쳐서 보여줌
# split 옵션 =>
sns.violinplot(x='day', y='total_bill', data=tips, hue='smoker', split=True)
plt.title('violinplot')
plt.show()
2. countplot()
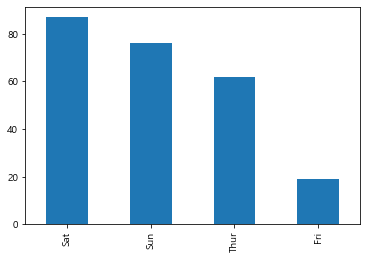
sns(seaborn)의 countplt 함수는기존 pandas의 columns 별 분포도를 확인하는 value_counts() 함수와 동일한 원리가 내포되어져 있다
value_counts()은 카테고리컬한 컬럼에 효과적인 함수,
tips['day'].value_counts().plot(kind='bar')
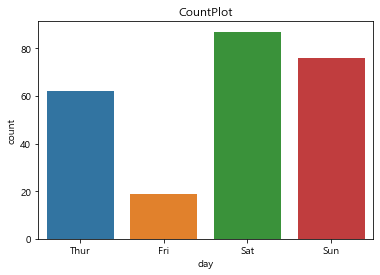
# 카테고리컬한 칼럼의 빈도수를 나타냄
sns.countplot(tips['day'])
plt.title('CountPlot')
plt.show()
3. Lmplot
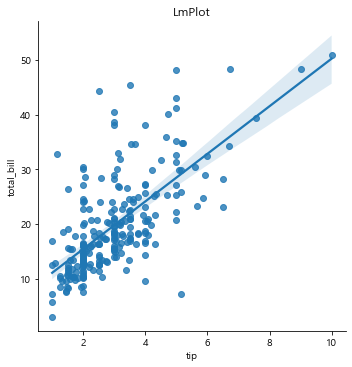
컬럼간의 선형적인 관계를 나타내는 그래프
선 상에 데이터가 찍혀야 선형 관계를 가진다. 음식 지불 금액이 높아질 수록 팁 금액이 높아지는 것
'''
컬럼들간의 선형 관계를 나타낸다는 의미는
직선상에 데이터들이 따닥따닥 붙어서 나와야 한다는 의미이다.
지금은 선상에 데이터들이 다소 넓게 퍼져서 나타난다.
그 이유는 온갖 데이터들이 섞여져서 그렇다..
tip에 성별, 요일, 인원수, 시간 모두 영향을 미칠 수 있기 때문에
hue 옵션을 사용해서 다중적인(여러 개의 칼럼) 선형관계를 조금 더 디테일하게 표시
'''
# 선형 관계를 입증하기 위해 팀과 상관관계가 높은 지불 금액을 넣자
sns.lmplot(x='tip', y='total_bill', data=tips)
plt.title('LmPlot')
plt.show()
# 음식값과 팁 금액이 어느정도 상관관계가 있다
# 다중적인(여러 개의 칼럼) 선형관계를 위한 hue 옵션을 추가해서 보자
sns.lmplot(x='tip', y='total_bill', data=tips, hue='smoker', height=8) # height 크기 키우기
plt.title('LmPlot')
plt.show()
# 흡연/비흡연자의 음식 지불 금액과 팁 금액의 관계
# 선형 관계에서 확인할 수 있는 것?
# 팁과 음식 지불 금액간의 선형 관계에 충실한 그룹이 '비흡연자'
# 비싼 음식 먹고도 팁을 적게 주는 흡연자 그룹은.. 담배 사느라 팁을 아꼈을까..?
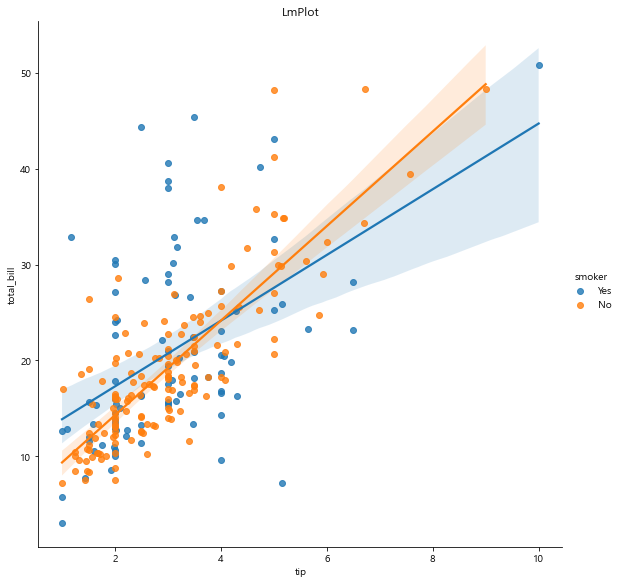
# col 옵션으로 분할해서 확인
sns.lmplot(x='tip', y='total_bill', data=tips,
hue='smoker', # 그룹핑, hue 옵션에서 흡연/비흡연자로 나누고
col='day', # 요일별로 분할하여 그래프 보여줘라
height=8) # height 크기 키우기
plt.title('LmPlot')
plt.show()
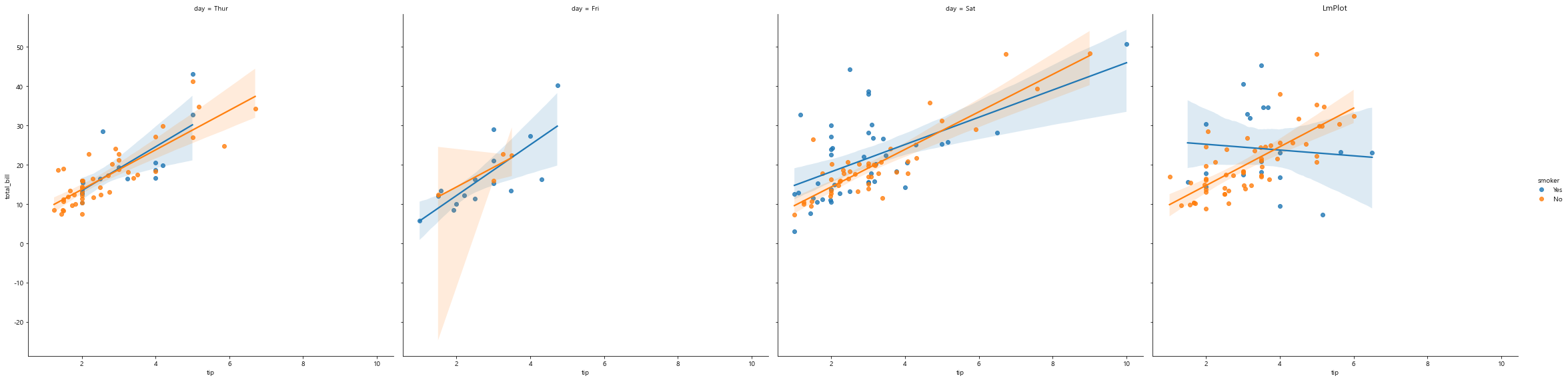
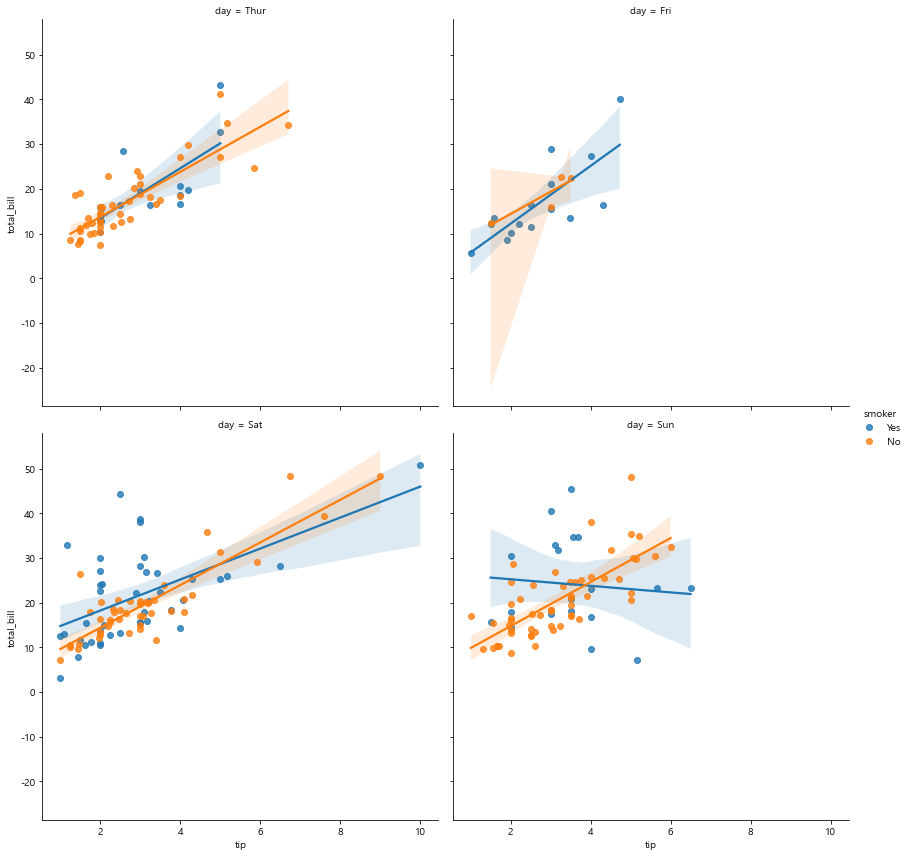
# col_wrap=2 옵션으로 옆으로 2개씩 보여주고 다음 줄로 넘어가라. 분할해서 확인
# 요일별 선형관계를 다시 살펴볼 수 있다
sns.lmplot(x='tip', y='total_bill', data=tips,
hue='smoker', # 그룹핑, hue 옵션에서 흡연/비흡연자로 나누고
col='day', # 요일별로 분할하여 그래프 보여줘라
col_wrap=2,
height=6) # height 크기 키우기
#plt.title('LmPlot')
plt.show()
4. relplot
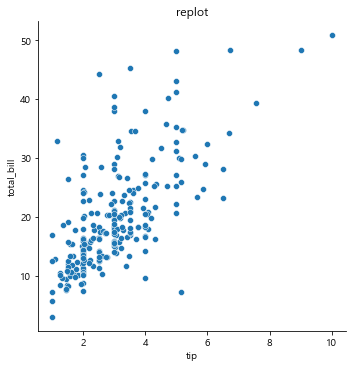
column간 상관관계
단, 선형관계를 따로 그려주지는 않는다.
# total_bill과 tip의 상관관계를 볼 수 있다
sns.relplot(x='tip', y='total_bill', data=tips)
plt.title('replot')
plt.show()
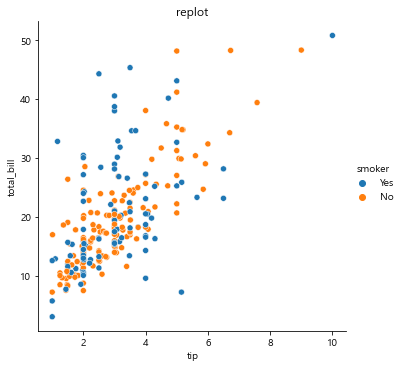
sns.relplot(x='tip', y='total_bill', data=tips, hue='smoker') # 흡연, 비흡연 나누어 비교 분석, legend 알아서 생성됨
plt.title('replot')
plt.show()
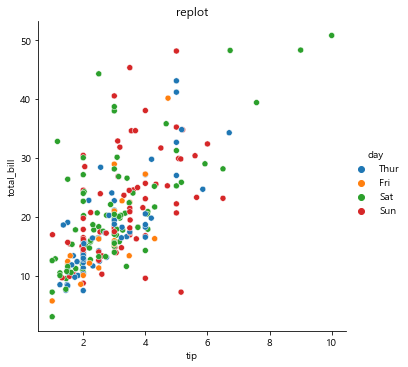
sns.relplot(x='tip', y='total_bill', data=tips, hue='day') # 요일별로 나누어 비교 분석, legend 알아서 생성됨
plt.title('replot')
plt.show()
sns.relplot(x='tip', y='total_bill', data=tips,
hue='day',# 요일별로 나누어 비교 분석, legend 알아서 생성됨
col='day')
plt.title('replot')
plt.show()
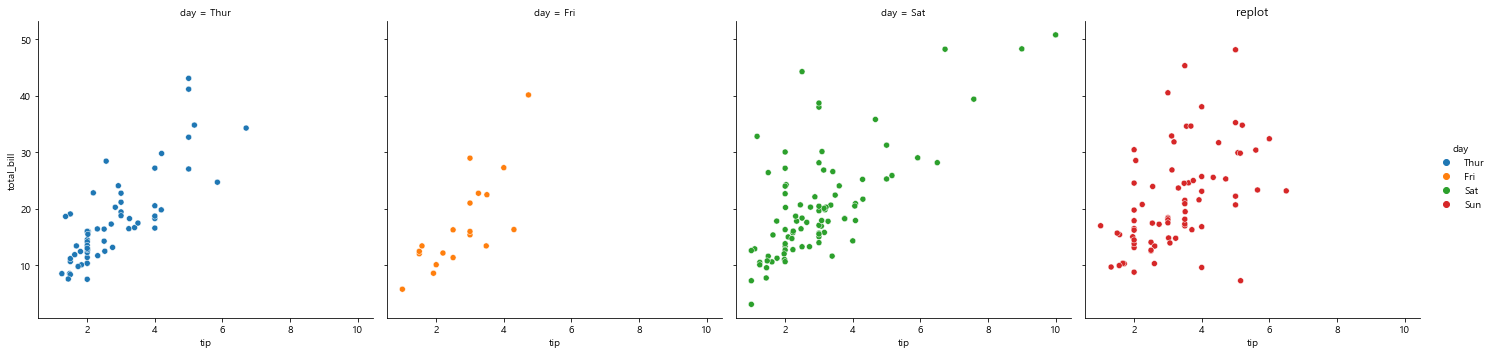
hue 옵션과 col 옵션으로 데이터프레임 통계 분석만으로 볼 수 없는 데이터 결과를 확인할 수 있다
목요일은 lunch밖에 안 해!! 그래서 time으로 나누면 lunch와 dinner 두 가지가 존재하는 목요일만 따로 그래프 만들어짐
sns.relplot(x='tip', y='total_bill', data=tips,
hue='day',# 요일별로 나누어 비교 분석, legend 알아서 생성됨
col='time')
plt.title('replot')
plt.show()
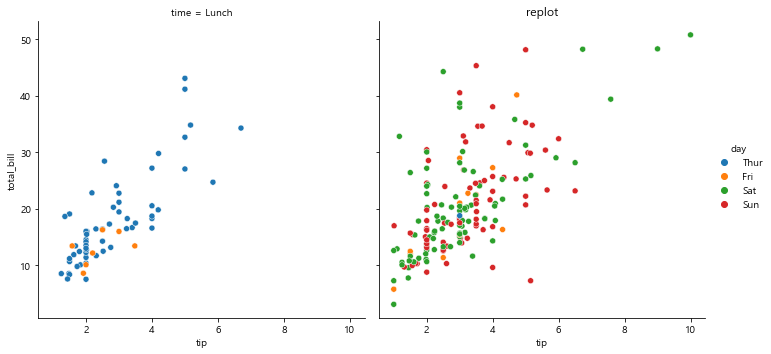
row, column에 표기할 데이터를 다시 명시
lunch에 남성과 여성 dinner에 남성과 여성을 나누어 확인 가능
'''
row는 성별 분할
col은 타임(lunch/dinner) 분할
'''
sns.relplot(x='tip', y='total_bill', data=tips,
hue='day',# 요일별로 나누어 비교 분석, legend 알아서 생성됨
col='time',# time(lunch/dinner)으로 구분하여 col 열로 나누어 보여줘
row='sex' # 성별로 구분하여 row 행으로 나누어 다시 분류(첫째 행은 Male, 둘째 행은 Female)
#palette='Accent'
palette='seismic'
)
plt.show()
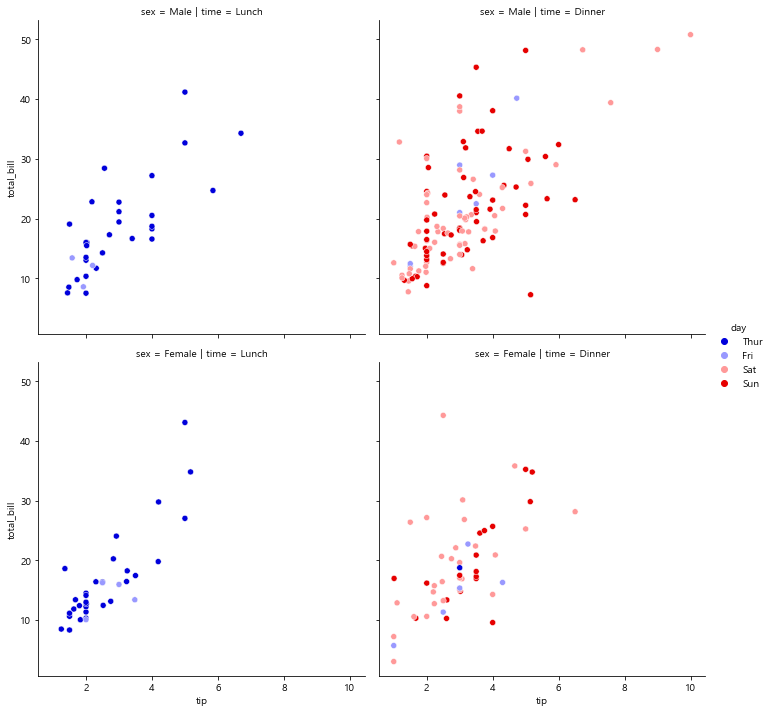
matplot 활용한 그래프를 Seaborn으로
matplot의 기본 색상보다 seaborn은 스타일링에 크게 신경쓰지 않아도 default컬러가 이쁘게 조합해 준다
5. barplot
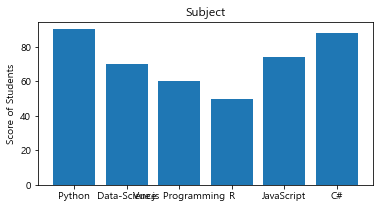
x = ['Python','Data-Science', 'Vue.js Programming','R', 'JavaScript', 'C#']
y = [90, 70, 60, 50, 74, 88]
plt.figure(figsize=(6,3))
plt.bar(x,y)
# plt.bar(x,y,align='center', alpha=0.7, color='red')
plt.ylabel('Score of Students')
plt.title('Subject')
matplot은 색이 별로.. 잘 안 쓰임..
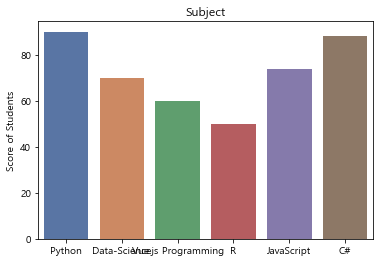
sns.barplot(x, y)
plt.ylabel('Score of Students')
plt.title('Subject')
sns.barplot(x, y, palette='deep')
plt.ylabel('Score of Students')
plt.title('Subject')
seaborn은 색이 더 예쁘다!
palette='deep' 속성 지정
컬러 팔레트
자세한 컬러 팔레트는 공식 도큐먼트 참고 합니다.
팔레트 작성 참고사이트는 이곳도 참고.
색상과 데이터 분석의 관계가 높아서 가독력, 설득력 높아짐
🚀 로켓 팔레트 만들기
sns.palplot(sns.color_palette("rocket", 10)) # 10칸 나오게

sns.barplot(x='tip', y='total_bill', data=tips) # 기본 색상
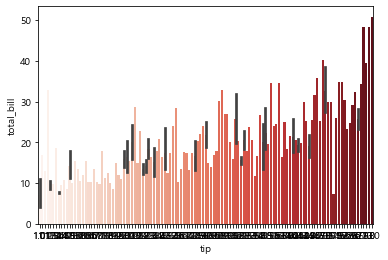
# 분석 결과에 색상 입혀서 잘 보이게
sns.barplot(x='tip', y='total_bill', data=tips, palette='Reds')
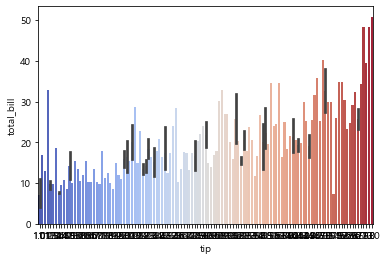
- 색상 종류 선택하기
- 'Accent', 'Accent_r', 'Blues', 'Blues_r', 'BrBG', 'BrBG_r', 'BuGn', 'BuGn_r', 'BuPu', 'BuPu_r', 'CMRmap', 'CMRmap_r', 'Dark2', 'Dark2_r', 'GnBu', 'GnBu_r', 'Greens', 'Greens_r', 'Greys', 'Greys_r', 'OrRd', 'OrRd_r', 'Oranges', 'Oranges_r', 'PRGn', 'PRGn_r', 'Paired', 'Paired_r', 'Pastel1', 'Pastel1_r', 'Pastel2', 'Pastel2_r', 'PiYG', 'PiYG_r', 'PuBu', 'PuBuGn', 'PuBuGn_r', 'PuBu_r', 'PuOr', 'PuOr_r', 'PuRd', 'PuRd_r', 'Purples', 'Purples_r', 'RdBu', 'RdBu_r', 'RdGy', 'RdGy_r', 'RdPu', 'RdPu_r', 'RdYlBu', 'RdYlBu_r', 'RdYlGn', 'RdYlGn_r', 'Reds', 'Reds_r', 'Set1', 'Set1_r', 'Set2', 'Set2_r', 'Set3', 'Set3_r', 'Spectral', 'Spectral_r', 'Wistia', 'Wistia_r', 'YlGn', 'YlGnBu', 'YlGnBu_r', 'YlGn_r', 'YlOrBr', 'YlOrBr_r', 'YlOrRd', 'YlOrRd_r', 'afmhot', 'afmhot_r', 'autumn', 'autumn_r', 'binary', 'binary_r', 'bone', 'bone_r', 'brg', 'brg_r', 'bwr', 'bwr_r', 'cividis', 'cividis_r', 'cool', 'cool_r', 'coolwarm', 'coolwarm_r', 'copper', 'copper_r', 'crest', 'crest_r', 'cubehelix', 'cubehelix_r', 'flag', 'flag_r', 'flare', 'flare_r', 'gist_earth', 'gist_earth_r', 'gist_gray', 'gist_gray_r', 'gist_heat', 'gist_heat_r', 'gist_ncar', 'gist_ncar_r', 'gist_rainbow', 'gist_rainbow_r', 'gist_stern', 'gist_stern_r', 'gist_yarg', 'gist_yarg_r', 'gnuplot', 'gnuplot2', 'gnuplot2_r', 'gnuplot_r', 'gray', 'gray_r', 'hot', 'hot_r', 'hsv', 'hsv_r', 'icefire', 'icefire_r', 'inferno', 'inferno_r', 'jet', 'jet_r', 'magma', 'magma_r', 'mako', 'mako_r', 'nipy_spectral', 'nipy_spectral_r', 'ocean', 'ocean_r', 'pink', 'pink_r', 'plasma', 'plasma_r', 'prism', 'prism_r', 'rainbow', 'rainbow_r', 'rocket', 'rocket_r', 'seismic', 'seismic_r', 'spring', 'spring_r', 'summer', 'summer_r', 'tab10', 'tab10_r', 'tab20', 'tab20_r', 'tab20b', 'tab20b_r', 'tab20c', 'tab20c_r', 'terrain', 'terrain_r', 'turbo', 'turbo_r', 'twilight', 'twilight_r', 'twilight_shifted', 'twilight_shifted_r', 'viridis', 'viridis_r', 'vlag', 'vlag_r', 'winter', 'winter_r'
6. catplot
Categorical plots를 모두 그릴 수 있음
bar plot은 무조건 평균이 출력됨!! grouping 함수의 default가 mean이기 때문에
# 남여, 흡연 비흡연자에 따른 총 음식 지불 금액에 대한 평균
sns.catplot(x='sex', y='total_bill', hue='smoker', data=tips, kind='bar') # 카테고리에 따른
plt.show()
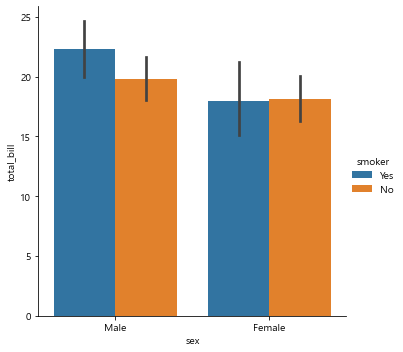
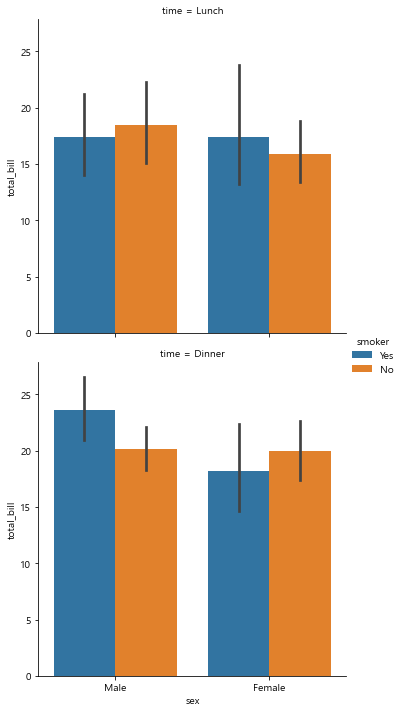
sns.catplot(x='sex', y='total_bill',
hue='smoker',
data=tips,
kind='bar',
row='time') # 카테고리에 따른
plt.show()
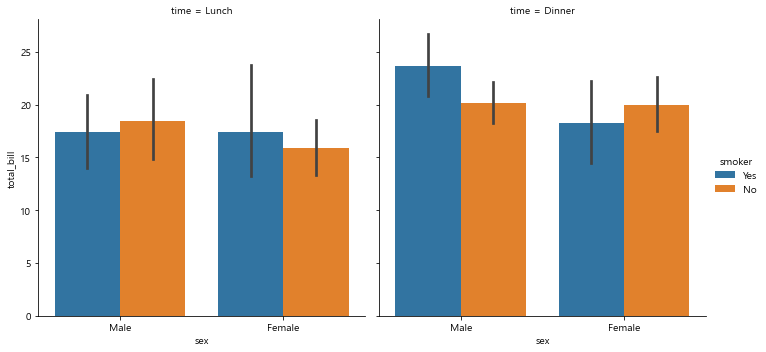
sns.catplot(x='sex', y='total_bill',
hue='smoker',
data=tips, kind='bar',
col='time') # 카테고리에 따른
plt.show()
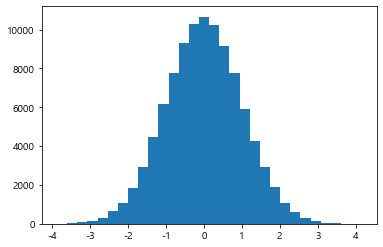
7. histogram distplot()
빈도수를 나타내는 대표적인 시각화 방법
N=100000
bins = 30
x = np.random.randn(N)
plt.hist(x, bins=bins)
plt.show()
sns.distplot(x, bins=bins, kde=False, color='g')
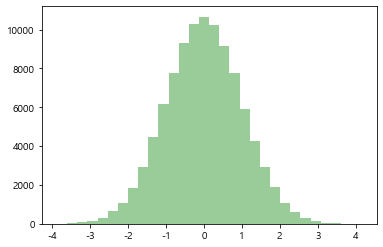
sns.distplot(x, bins=bins, kde=True, color='g')
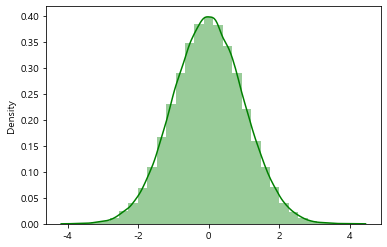
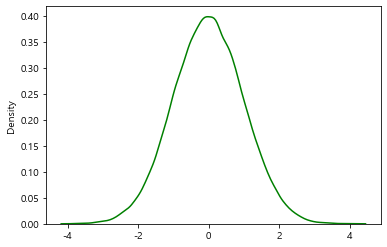
sns.distplot(x, bins=bins, kde=True,
color='g',
hist=False) # kde만 보이게
8. heatmap
상관관계가 1에 가까울 수록 진하게 표시된다.
상관계수는 일반적으로
값이 -1.0 ~ -0.7 이면, 강한 음적 상관관계
값이 -0.7 ~ -0.3 이면, 뚜렷한 음적 상관관계
값이 -0.3 ~ -0.1 이면, 약한 음적 상관관계
값이 -0.1 ~ +0.1 이면, 없다고 할 수 있는 상관관계
값이 +0.1 ~ +0.3 이면, 약한 양적 상관관계
값이 +0.3 ~ +0.7 이면, 뚜렷한 양적 상관관계
값이 +0.7 ~ +1.0 이면, 강한 양적 상관관계로 해석된다.
0.3 만 넘어도 상관관계가 상당하다!!
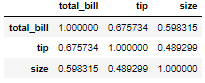
tips.corr()
sns.heatmap(tips.corr(), annot=True) # annot으로 숫자 넣기
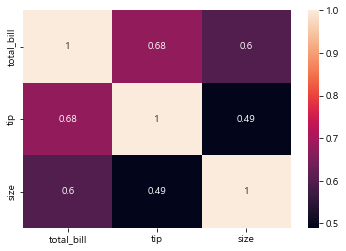
- total_bill과 tip 사이의 상관관계 높다
- total_bill과 size 역시 상관관계 있다
밝을수록 상관관계 높고, 어두울 수록 상관관계 낮다
위의 예제는 데이터가 적어서 상관관계 잘 안 보임
타이타닉 데이터 받아오자!
칼럼 간의 상관관계가 복잡해서 한 눈에 알아보기 힘들 때 heatmap 사용

titanic = sns.load_dataset('titanic')
titanic.corr()
heatmap을 할 때 음의 상관관계는 양수로 변환해야 한다
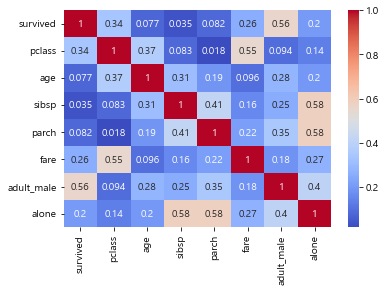
sns.heatmap(titanic.corr(), annot=False)
우리가 알고 있는 것처럼 생존율과 높게 나온 것은 slingspause, parench 상관관계가 원래는 낮게 나와야 한다.
정확한 지표를 보기 위해서는 annot=True로 숫자가 표현되게 하고
추가 abs() 함수를 이용해서 음의 값을 다 절댓값으로 치환
sns.heatmap(abs(titanic.corr()), annot=True)
'''
타이타닉 데이터는 컬럼 간의 상관관계를 정확하게 분석하기에 그다지 좋은 데이터는 아니다
선형 관계를 가지는 데이터를 상관 관계로 보는 게 효율적이다.
heatmap을 효과적으로 사용할 때
예를 들어 특정 기업의 매출액, 서울시 주택가격 동향과 같은 연속적인 숫자 데이터를 가지는 것을 나타내는 시각화..
'''
# seaborn에서 palette가 안 먹힐 때가 있다 그럴 땐 cmap을 사용해야 한다.
sns.heatmap(abs(titanic.corr()), annot=True, cmap='coolwarm')
'''
heatmap에는 이런 데이터를 넣어줘야 한다!
년도별, 월별 항공기 탑승 승객의 추이...
'''
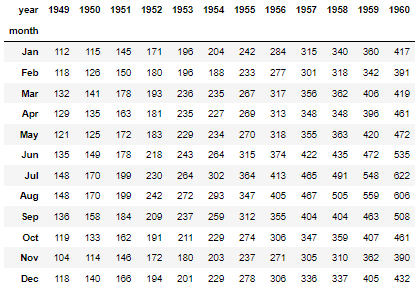
flights = sns.load_dataset('flights')
# dataframe의 shape을 변경하는 pivot_table() 사용
flights.head()
flights = flights.pivot_table(index='month', columns='year', values='passengers') # 재대입 필수
flights
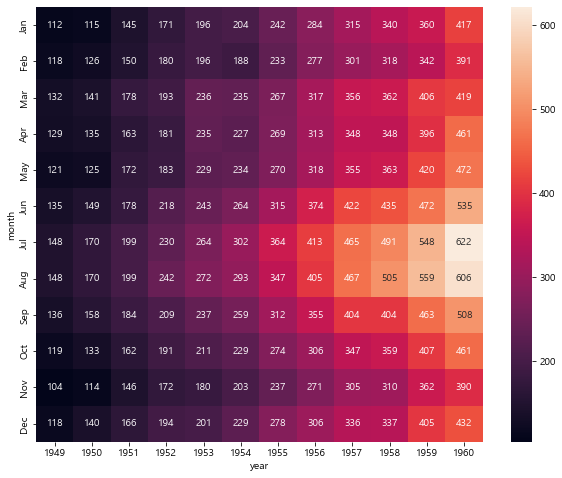
plt.figure(figsize=(10,8))
sns.heatmap(flights, annot=True, fmt='d')
plt.show()
# 연도가 올라갈 수록 색이 연해지는 걸 보아하니 비행기 탑승 인원이 많아졌다
# 여름 휴가철에 비행기 탐승 인원이 많아졌다
plt.figure(figsize=(10,8))
sns.heatmap(flights, annot=True, fmt='d', cmap='Blues')
plt.show()
# 연도가 올라갈 수록 비행기 탑승 인원이 많아졌다, 색상을 변경하여 색이 진할 수록 빈도가 많은 것으로 변경됨
# 여름 휴가철에 비행기 탐승 인원이 많아졌다
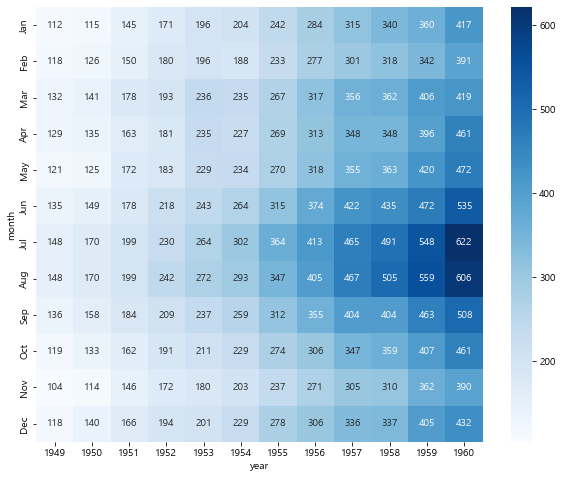
9. pairplot
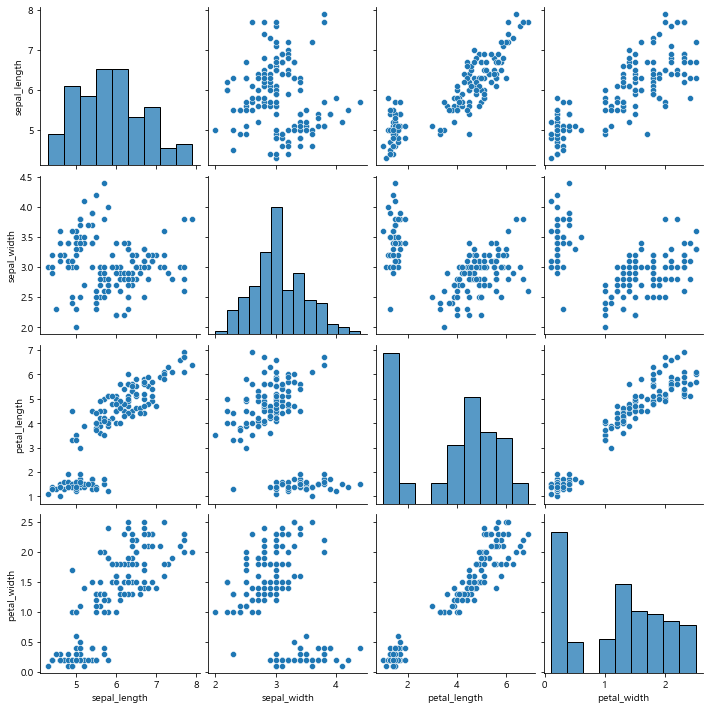
상관관계를 볼 수 있는 대표적인 그래프
# 붓꽃의 종류, 품종의 상관관계를 볼 때 사용
iris = sns.load_dataset('iris')
iris.head()
plt.figure(figsize=(6,4))
sns.pairplot(iris) # seaborn에서 제공하는 독보적인 상관관계 볼 수 있는
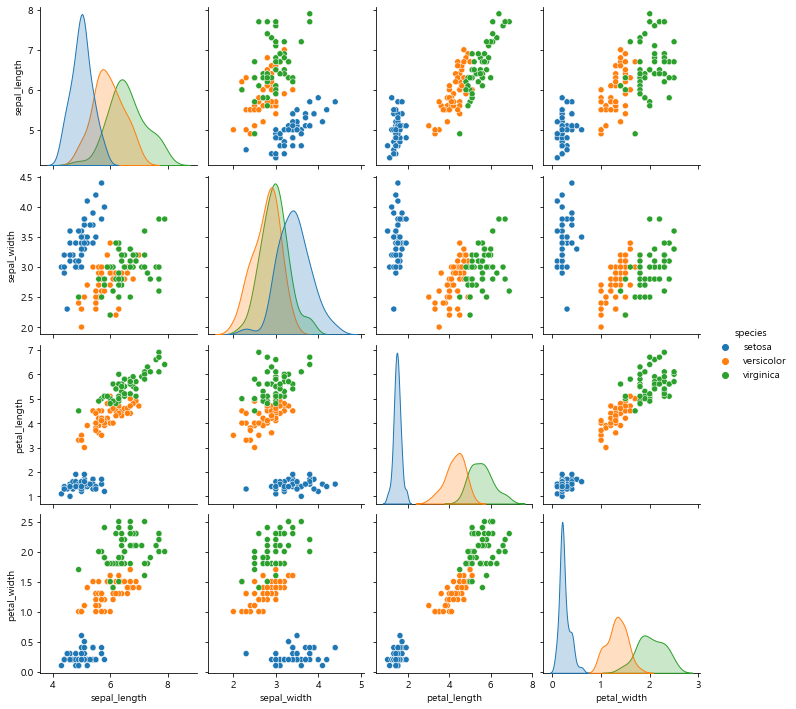
갈라치기 hue!!!!
plt.figure(figsize=(6,4))
sns.pairplot(iris, hue='species') # seaborn에서 제공하는 독보적인 상관관계 볼 수 있는
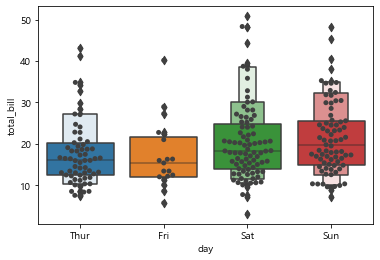
10. swarmplot
swarmplot은 boxplot과 함께 사용되어서
이상치 값들이 어디에 어떻게 분포되어져 있는지와
50% 안에 들어가 있는 값들의 분포도 좀 더 직관적으로 확인 가능
sns.boxenplot(x='day', y='total_bill', data=tips)
sns.swarmplot(x='day', y='total_bill', data=tips, color='.25')
plt.show()
# 이상치 값을 도드라지게 보일 수 있는 boxplot과 같에 쓰임
# 중앙값을 기준으로 상위25, 하위 25% 값을 볼 수 있고
# 이상치 값을 어떻게 처리해야 하는지 직감이 와!
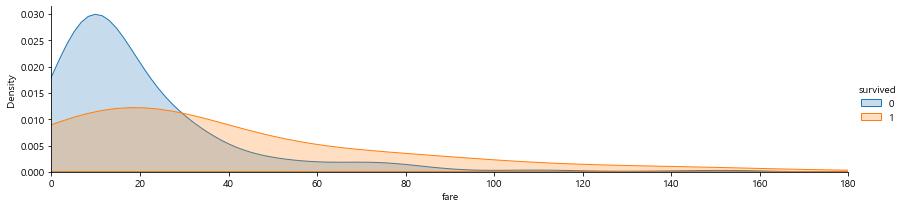
11. FacetGrid
다양한 범주형 값을 가지는 데이터를 시각화하는데 좋은 방법
titanic = sns.load_dataset('titanic')
titanic.head(1)
# 1이 생존, 0이 사망
facet = sns.FacetGrid(titanic, hue="survived",aspect=4)
facet.map(sns.kdeplot,'fare',shade= True)
facet.set(xlim=(0, titanic['fare'].max()))
facet.add_legend()
plt.xlim(0,180)
plt.show()
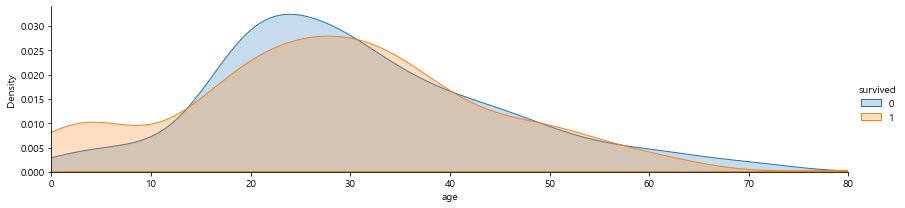
타이타닉 데이터에서 age 값에 결측값이 많다.
따라서 이 결측값을 평균값으로 채우겠지만 성능이 무지 떨어진다 😢
그럴 때 구획화하여 범주의 구간을 나눈다!
facet = sns.FacetGrid(titanic, hue="survived",aspect=4)
facet.map(sns.kdeplot,'age',shade= True)
facet.set(xlim=(0, titanic['age'].max()))
facet.add_legend()
plt.show()
0~13세까지의 생존률은 최대한 살리려고 했을 것이다.
14세~30세까지 사망률이 높다
'Python > 데이터 분석' 카테고리의 다른 글
| [Matplotlib] Matplot을 이용한 시각화 (0) | 2022.04.09 |
|---|---|
| [Pandas] Pandas - plot (0) | 2022.04.09 |
| [Dataframe] Dataframe - 데이터 병합 (0) | 2022.04.09 |
| [DataFrame] DataFrame - Grouping, pivot_table (0) | 2022.04.08 |
| [DataFrame] DataFrame - 통계 함수, 날짜 변수 (0) | 2022.04.08 |




댓글