Matplot
파이썬으로 데이타를 시각화 하는데는 matplotlib 라는 라이브러리를 가장 많이 사용matplotlib은 파이썬에서 2D 형태의 그래프, 이미지 등을 그릴때 사용하는 것으로실제 과학 컴퓨팅 분야나 인공지능 연구분야에서도 많이 사용됨
matplotlib 모듈 중에는 다양한 모듈들이 있는데 그 중에서 가장 많이 사용하는서브모듈이 pyplot 이다.
import matplotlib.pyplot as plt
matplot의 서브 모듈인 pyplot을 사용한다.
1. 직선 그래프 그리기

plot(), subprot(), subplots()
x = np.arange(10)
plt.plot(x) # 원래는 x, y 형식으로 넣어줘야 하는데 매개변수 하나만 넣으면 x와 y 동일하게 들어가서 대각선 출력
plt.show() # default로 하나의 캔버스 안에 하나의 그래프만 그림
하나의 Cavas안에 다중 그래프
plt.plot()을 여러번
x1 = np.arange(10)
plt.plot(x1)
x2 = np.arange(10,20) # 10에서 19까지
plt.plot(x2)
plt.show() # 캔버스는 하나지만 그래프는 두 개 그려짐
Canvas를 여러개
2개의 figure로 나눠서 그래프 그리기 ⇒ 비효율적인 방법!
- canvas 여러 개를 그리면 그래프가 생각보다 큰 영역을 차지하면서 그려지기 때문에 다소 비효율적이다.
- figure는 새로운 canvas를 생성한다.
x1 = np.arange(100,200)
plt.plot(x1, 'r') # r 속성으로 빨간색으로 설정
x2 = np.arange(201,300)
plt.figure() # 새로운 canvas가 만들어진다. 각각의 figure 만들기
plt.plot(x2)
plt.show()
- subplot() 함수 사용하기 ⇒ 1.번의 문제점을 보완하기 위해 canvas를 하나만 만들고 canvas 자체를 2등분 혹은 3등분 하는 방법을 사용한다.
여러개의 plot을 그리는 방법 1
subplot(row, column, index)
x1 = np.arange(100,201)
# 무조건 앞에 나오는 건 행, 뒤에 나오는 건 열
# 2행 1열 중에 첫 번째 행에 그려져라
plt.subplot(2,1,1)
plt.plot(x1)
x2 = np.arange(201,301)
# 2행 1열 중에 두 번째 행에 그려져라
plt.subplot(2,1,2)
plt.plot(x2)
subplot(row, column, index)에서 인자의 콤마를 제거해도 동일한 결과
x1 = np.arange(100,201)
# 2행 1열 중에 첫 번째 행에 그려져라 => 콤마제거
plt.subplot(211)
plt.plot(x1)
x2 = np.arange(201,301)
# 2행 1열 중에 두 번째 행에 그려져라
plt.subplot(212)
plt.plot(x2)
plt.show()
세로로 구분
하나의 canvas를 세로로 3등분하기
x1 = np.arange(100,201)
x2 = np.arange(201,301)
x3 = np.arange(301,401)
# 1행 3열 첫번째
plt.subplot(131)
plt.plot(x1)
# 1행 3열 두번째
plt.subplot(132)
plt.plot(x2)
# 1행 3열 세번째
plt.subplot(133)
plt.plot(x3)
plt.show()
여러개의 plot을 그리는 방법 2
subplots() s가 붙는다.
plt.subplots(행의 갯수, 열의 갯수)
⇒ 매개변수가 두 개뿐!! 몇 번째인지 명시 안 해줘도 됨,
why? fig(canvas 자체)와 axis가 반환된다!!
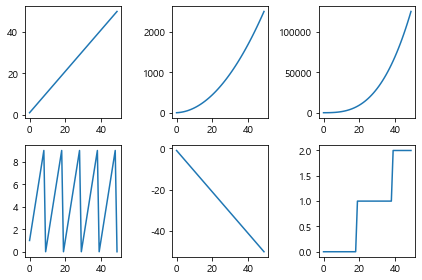
x = np.arange(1, 51)
fig, axis = plt.subplots(2,3) # 2행 3열로 만들어라
#fig(canvas 자체)와 axis가 반환된다!!
axis[0,0].plot(x)
axis[0,1].plot(x * x)
axis[0,2].plot(x ** 3)
axis[1,0].plot(x % 10)
axis[1,1].plot(-x)
axis[1,2].plot(x // 20)
# tight_layout 속성으로 그래프 간격 조정
plt.show()
그래프가 예쁘게 안 나오고 범례가 다른 그래프에 침범해!
- figsize
- tight_layout : 그래프 사이사이 간격 조정
2. 여러가지 옵션들
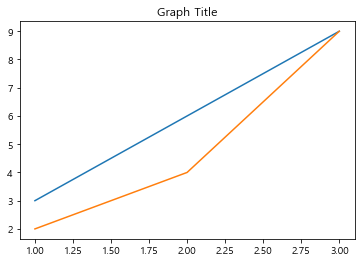
title
plt.plot([1,2,3],[3,6,9])
plt.plot([1,2,3],[2,4,9])
plt.title('Graph Title', fontsize=20)
plt.show()
x,y축 라벨지정
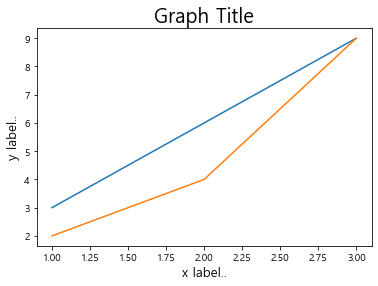
plt.plot([1,2,3],[3,6,9])
plt.plot([1,2,3],[2,4,9])
plt.title('Graph Title', fontsize=20)
plt.xlabel('x label..', fontsize=13)
plt.ylabel('y label..', fontsize=13)
plt.show()
x,y Tick설정(rotation)
tick은 x,y축에 위치한 눈금입니다.
legend 범례
x,y범위 한정짓기 Limited
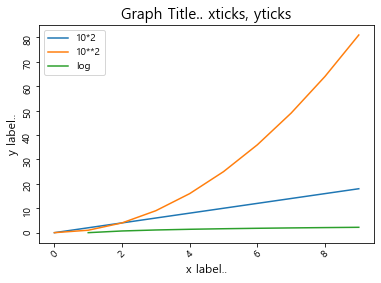
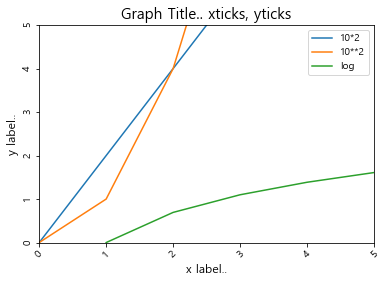
plt.plot(np.arange(10), np.arange(10)*2)
plt.plot(np.arange(10), np.arange(10)**2)
plt.plot(np.arange(10), np.log(np.arange(10)))
plt.title('Graph Title.. xticks, yticks', fontsize=15)
plt.xlabel('x label..', fontsize=12)
plt.ylabel('y label..', fontsize=12)
# x축 값들이 서로 겹치지 않도록 각도를 45도 기울게 설정
plt.xticks(rotation=45)
plt.yticks(rotation=90)
# 범례 지정
plt.legend(['10*2','10**2','log'])
# limit 속성
plt.xlim(0,5) # 0~5만 보이게 확대, 돋보기 기능
plt.ylim(0,5,10)
plt.show()
3. matplot 활용한 다양한 그래프 그리기
1. Scatterplot
0~1사이의 임의의 랜덤한 50개의 값들을 생성
x,y,colors, area 설정하기
- colors는 임의의 color값을 설정
- area는 점의 넓이를 지정. 값이 커지면 넓이고 따라서 커짐.
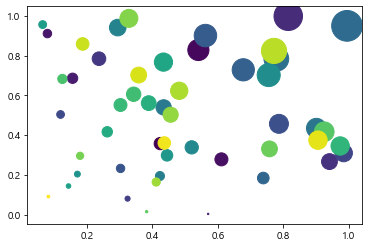
x = np.random.rand(50)
y = np.random.rand(50)
colors = np.arange(50)
area = x*y*1000
plt.scatter(x,y,s=area, c=colors)
plt.scatter(x,y,s=area, cmap='blue', alpha=1) # cmap이라는 칼럼에 색상 지정
산점도에 투명도를 지정하면
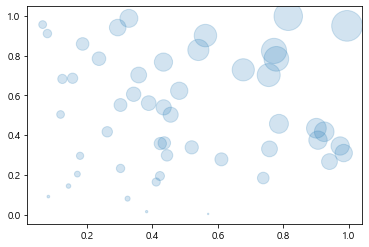
데이터들이 겹쳐지는 부분에서 진하게 표시되기 때문에 데이터들의 분포를 좀 더 직관적으로 확인할 수 있다.
alpha : 0~1 사이의 값을 가짐(1에 가까울수록 불투명도, 0~~ )
s : 마커의 강도
# 투명도를 사용해서 얼마나 겹쳐 보이는지 볼 수 있음
plt.scatter(x,y,s=area, cmap='blue', alpha=0.2) # cmap이라는 칼럼에 색상 지정
2. Barplot, Barhplot
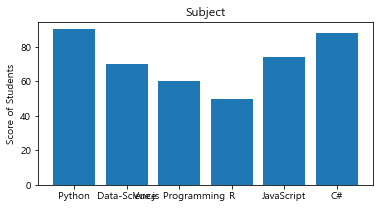
x = ['Python','Data-Science', 'Vue.js Programming','R', 'JavaScript', 'C#']
y = [90, 70, 60, 50, 74, 88]
plt.figure(figsize=(6,3))
plt.bar(x,y)
plt.ylabel('Score of Students')
plt.title('Subject')
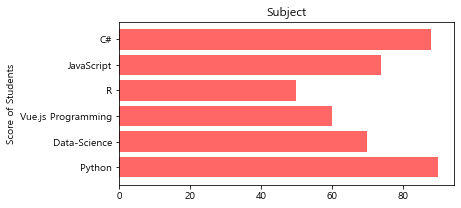
x = ['Python','Data-Science', 'Vue.js Programming','R', 'JavaScript', 'C#']
y = [90, 70, 60, 50, 74, 88]
plt.figure(figsize=(6,3))
plt.barh(x,y, color='red', alpha=0.6)
plt.ylabel('Score of Students')
plt.title('Subject')
3. histogram
특정 범위에 따른 분포를 볼때 많이 사용
히스토그램 (Histogram)은 도수분포표를 그래프로 나타낸 것으로서,
가로축은 계급(bins), 세로축은 도수 (횟수나 개수 등)를 나타낸다.
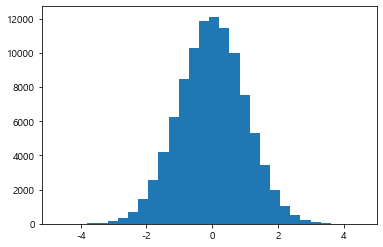
'''
정규분포의 값
0에 해당하는 값의 분포가 가장 높고,
양 가쪽으로 갈수록 데이터의 분포가 점점 떨어지는 것을 확인
'''
N = 100000
bins = 30 # 30개로 쪼갬
x = np.random.randn(N) # 구간, randn을 써서 0에 해당하는 빈도가 가장 높음
plt.hist(x, bins=bins)
plt.show()
구간 개수 지정하기
hist() 함수의 bins 파라미터는 히스토그램의 가로축 구간의 개수를 지정합니다.
아래 그림과 같이 구간의 개수에 따라 히스토그램 분포의 형태가 달라질 수 있기 때문에
적절한 구간의 개수를 지정해야 합니다.
구간을 쪼개면 상대적으로 빈도가 낮아진다. 구간이 넓어질 수록 빈도가 높아진다.
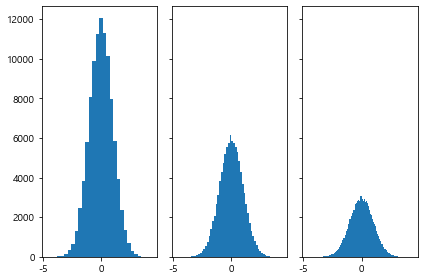
# 구간의 변동에 따른 빈도수의 값의 차이
'''
bins의 갯수를 점점 늘려줬다.. 2배, 4배
정확한 비율로 빈도의 갯수가 그만큼 줄어든 것을 확인
'''
N = 100000
bins = 30 # 30개로 쪼갬
x = np.random.randn(N)
# 1행 3열
fig, axis = plt.subplots(1,3, sharey=True, tight_layout=True)# y축 통일시키기, 그래프마다의 간격 조정
# 1행 뿐이기 때문에 행만 넣어주면 됨
axis[0].hist(x, bins=bins)
axis[1].hist(x, bins=bins*2)
axis[2].hist(x, bins=bins*4)
# 균일한 간격 주기
# plt.tight_layout()
# 인치로 canvas 사이즈 조정
#fig.set_size_inches(10,3)
# 튜플로 크기 조정
#plt.figure(figsize=(8,6))
plt.show()
4. Pieplot
pip chart 옵션 (pandas에서는 plot(kind=’pie’)로 사용했음
- explode : 파이에서 조각으로 튀어져 나온 비율
- autopct : 퍼센트 자동으로 표기
- shadow : 그림자 표시
- startangle : 파이를 그리기 시작할 각도
texts, autotexts 인자를 리턴 받는다
texts는 label에 대한 텍스트 효과를
autotexts는 파이 위에 그려지는 텍스트 효과를 다룰 때 활용
labels = ['KB Bank','SH Bank','WOORI Bank','NH Bank','HN Bank','Etc']
sizes=[20.4, 20.1, 10.3, 8.0, 7.8, 15]
explode = (0.3,0,0,0,0,0)
# label 텍스트, pie 위에 적힘
patches, texts, autotexts=plt.pie(
sizes,
explode=explode,
labels = labels,
autopct='%1.1f%%', # 10.2 20.4 처럼 나오게끔
shadow=True,
startangle=90
)
plt.title('금융자산 파이',fontsize=15)
# label 텍스트에 대한 옵션
for t in texts:
t.set_fontsize(15)
t.set_color('gray')
# pie 위에 적힐 텍스트에 대한 옵션
for t in autotexts:
t.set_fontsize(15)
t.set_color('pink')
'Python > 데이터 분석' 카테고리의 다른 글
| [Seaborn] Seaborn을 이용한 시각화 (0) | 2022.04.09 |
|---|---|
| [Pandas] Pandas - plot (0) | 2022.04.09 |
| [Dataframe] Dataframe - 데이터 병합 (0) | 2022.04.09 |
| [DataFrame] DataFrame - Grouping, pivot_table (0) | 2022.04.08 |
| [DataFrame] DataFrame - 통계 함수, 날짜 변수 (0) | 2022.04.08 |




댓글