
Ensemble (앙상블)
머신러닝 앙상블이란 여러개의 머신러닝 모델을 이용해 최적의 답을 찾아내는 기법이다.
- 여러 모델을 이용하여 데이터를 학습하고, 모든 모델의 예측결과를 평균하여 예측
앙상블 기법의 종류
- 보팅 (Voting)
- 서로 다른 알고리즘 분류가 결함됨
- 여러 모델의 예측 결과를 투표해서 최종적인 예측결과를 결정함
- 배깅 (Bagging)
- 샘플 중복 생성을 통해 결과 도출
- 샘플을 여러번 랜덤하게 뽑아서각 모델을 학습 시키고 그 결과를 집계함. 샘플링을 조합해서 학습하는 방식이 배깅기법. RandomForest가 배깅 알고리즘을 사용한 대표적인 모델이다.
- 부스팅 (Boosting)
- 이전 오차를 보완하면서 가중치 부여
- 여러 모델이 순차적으로 학습
- 일명 Weak Learner라 불린다.
- 스태킹 (Stacking)
- 여러 모델을 기반으로 예측된 결과를 통해 meta 모델이 다시 한번 예측
Ensemble 아이디어

한 명의 의견보다 여러 명의 의견의 절충안을 고려한다.
실습을 위한 데이터셋 로드 보스턴 집값
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
SEED = 30
from sklearn.datasets import load_boston
# DataFrame 생성
data = load_boston()
df = pd.DataFrame(data['data'], columns=data['feature_names'])
df['target'] = data['target']
df.head()
train / test 데이터를 분할 합니다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'],random_state=SEED)
x_train.shape # (379, 13)
모델별 성능 확인을 위한 함수
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_error
my_predictions = {}
my_pred = None
my_actual = None
my_name = None
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato'
]
def plot_predictions(name_, pred, actual):
df = pd.DataFrame({'prediction': pred, 'actual': y_test})
df = df.sort_values(by='actual').reset_index(drop=True)
plt.figure(figsize=(11, 8))
plt.scatter(df.index, df['prediction'], marker='x', color='r')
plt.scatter(df.index, df['actual'], alpha=0.7, marker='o', color='black')
plt.title(name_, fontsize=15)
plt.legend(['prediction', 'actual'], fontsize=12)
plt.show()
def mse_eval(name_, pred, actual):
global my_predictions, colors, my_pred, my_actual, my_name
my_name = name_
my_pred = pred
my_actual = actual
plot_predictions(name_, pred, actual)
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df) / 2
plt.figure(figsize=(9, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=12)
bars = ax.barh(np.arange(len(df)), df['mse'], height=0.3)
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=12, fontweight='bold', verticalalignment='center')
plt.title('MSE Error', fontsize=16)
plt.xlim(min_, max_)
plt.show()
def add_model(name_, pred, actual):
global my_predictions, my_pred, my_actual, my_name
my_name = name_
my_pred = pred
my_actual = actual
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
def remove_model(name_):
global my_predictions
try:
del my_predictions[name_]
except KeyError:
return False
return True
def plot_all():
global my_predictions, my_pred, my_actual, my_name
plot_predictions(my_name, my_pred, my_actual)
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df) / 2
plt.figure(figsize=(9, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=12)
bars = ax.barh(np.arange(len(df)), df['mse'], height=0.3)
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=12, fontweight='bold', verticalalignment='center')
plt.title('MSE Error', fontsize=16)
plt.xlim(min_, max_)
plt.show()
단일 회귀예측 모델
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
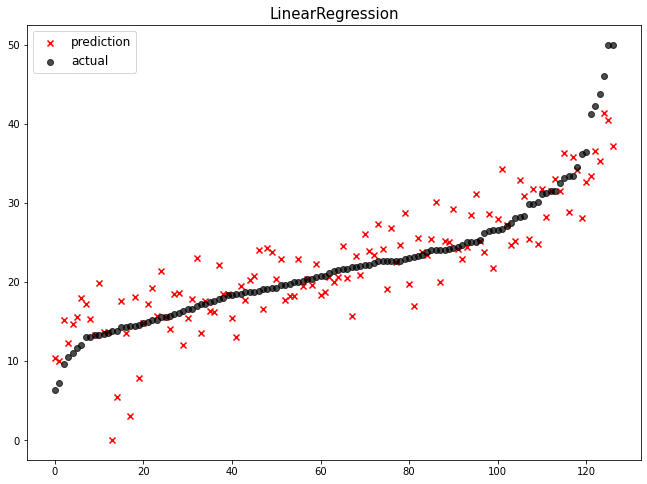
LinearRegression
- 기본 옵션 값을 사용하여 학습합니다.
linear_reg = LinearRegression()
linear_reg.fit(x_train, y_train)
pred = linear_reg.predict(x_test)
mse_eval('LinearRegression', pred, y_test)
# Polynomial feature을 통해 (차수를 높여서) 칼럼 간의 연산을 한다.
# degree=2 일 경우, 차수를 높여 새로운 컬럼을 바라볼 가능성이 생겨서 통합적인 칼럼을 찾을 수 있따
Ridge L2
- 규제 계수인 alpha=0.1을 적용합니다.
ridge = Ridge(alpha=0.1) # 규제를 적용한 선형..?
# 학습
ridge.fit(x_train, y_train)
pred = ridge.predict(x_test)
mse_eval('Ridge(alpha=0.1)', pred, y_test)
# 가중치의 weight를 높게 가진 것은 내리고, 낮게 가진 것은 높여서

Lasso L1
- 규제 계수인 alpha=0.01로 적용합니다.
# 규제가 가민 선형 회귀
lasso = Lasso(alpha=0.01)
lasso.fit(x_train, y_train)
pred = lasso.predict(x_test)
mse_eval('Lasso(alpha=0.01)', pred, y_test)
# Lasso의 성능 평가, 비선형적인 부분은 잘 못 갈라 ㅜ
# 현재 1위 Lasso

ElasticNet L1 위주로 줌(Lasso가 위에서 더 높게 나와써 ㅎㅎ)
- 규제 계수인 alpha=0.01, l1_ratio=0.8을 적용합니다.
elasticnet = ElasticNet(alpha=0.01, l1_ratio=0.8)
elasticnet.fit(x_train, y_train)
pred = elasticnet.predict(x_test)
mse_eval('ElasticNet(alpha=, l1_ratio=)', pred, y_test)
# ElasticNet

Pipeline 학습
StandardScaler와 ElasticNet의 파이프라인 학습 합니다.
- ElasticNet 모델은 규제 계수인 alpha=0.01, l1_ratio=0.8을 적용합니다.
StandardScaler와 MinMaxScaler 같이 쓰면 성능 떨어질 수 있음!
elasticnet_pipeline = make_pipeline(
StandardScaler(), # 전처리 진행
# 규제 강도 0.01
ElasticNet(alpha=0.01, l1_ratio=0.8)
)
elasticnet_pipeline.fit(x_train, y_train)
elasticnet_pred = elasticnet_pipeline.predict(x_test)
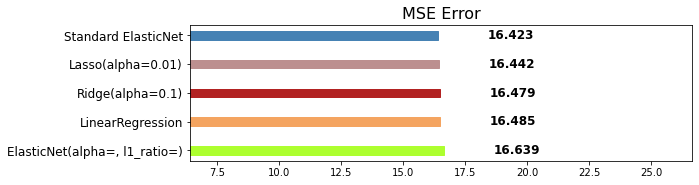
mse_eval('Standard ElasticNet', elasticnet_pred, y_test)
PolynomialFeatures
차수를 높여서 비선형적인 칼럼을 잘 예측함! 말도 안 되게 차수 높이면 칼럼 개수 너무 많아져! PolynomialFeatures와 ElasticNet의 파이프라인 학습을 진행합니다.
- PolynomialFeatures는 degree=2, include_bias=False로 적용합니다.
- ElasticNet 모델은 규제 계수인 alpha=0.1, l1_ratio=0.2을 적용합니다.
poly_pipeline = make_pipeline(
StandardScaler(),
PolynomialFeatures(degree=2, include_bias=False),
ElasticNet(alpha=0.1, l1_ratio=0.8)
)
poly_pipeline.fit(x_train, y_train)
poly_pred = poly_pipeline.predict(x_test)
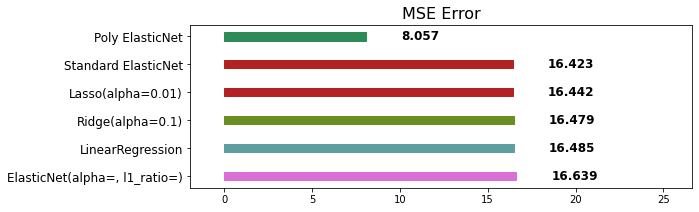
mse_eval('Poly ElasticNet', poly_pred, y_test)
# polynomial feautres 한 번으로 16%에서 8%가지 줄어듦!
# 여기서 Elastin 까지 조정하면 6%까지 내려갈 수 있을 것 같음!
# 차수를 높이고 sacling해서 데이터의 간극을 조정했더니 성능을 2배 이상으로 높임
앙상블 (Ensemble)
보팅 (Voting) - 회귀 (Regression)
Voting은 단어 뜻 그대로 투표를 통해 결정하는 방식입니다. Voting은 Bagging과 투표방식이라는 점에서 유사하지만, 다음과 같은 큰 차이점이 있습니다.
- Voting은 다른 알고리즘 model을 조합해서 사용합니다.
- Bagging은 같은 알고리즘 내에서 다른 sample 조합을 사용합니다.
Voting은 여러 가지 알고리즘을 섞는 건데 이것들을 리스트 안에다가 감싸줘야 한다.
list 안에 튜플 형식으로 넣어줘야 한다.
[ (’알고리즘’, 객체), (’알고리즘’, 객체), (’알고리즘’, 객체), .. ]
from sklearn.ensemble import VotingClassifier, VotingRegressor
single_models = [
('linear_reg', linear_reg),
('ridge', ridge),
('lasso', lasso),
('elasticnet_pipeline', elasticnet_pipeline),
('poly_pipeline', poly_pipeline)
]
#모델 생성
# 위에 정의하고 모아둔 여러가지 모델을 넣어줌, 지금부턴 시간 오래 걸리니까 CPU 코어 모두 사용하자
voting_regressor = VotingRegressor(single_models, n_jobs=-1)
# 학습
voting_regressor.fit(x_train, y_train)
# 예측
voting_pred = voting_regressor.predict(x_test)
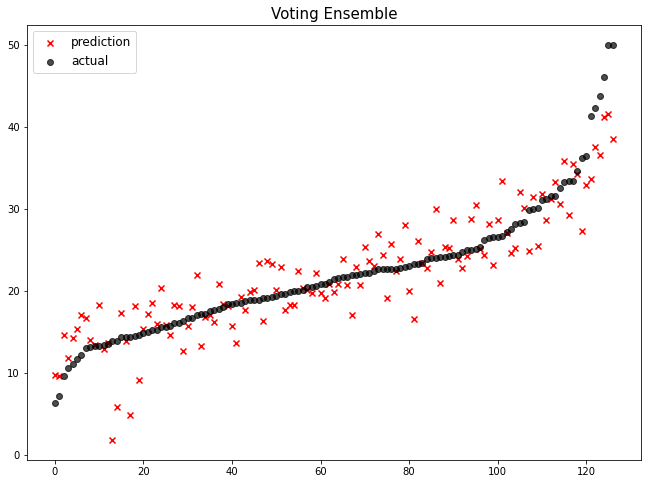
voting 앙상블의 실망스러운 점
- 아래 그래프 보면 오른쪽 값들을 처리해주지 못 함(까만 점들 ㅜㅜ)
- 값 튜닝도 안 해줬는데도 다른 애들보다 월등하게 성능이 좋긴 함!
- 앙상블했음에도 1등 성능이 나오지 않는 이유? standard, lasso, ridge 안 좋은 애들 묶어서 결과를 내니 작은 건 당연해! 그래도 안 좋은 애들을 튜닝 후에 묶으면 완전 어벤져스 될 수 있음!
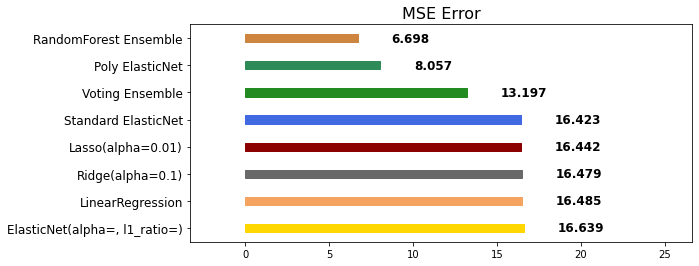
mse_eval('Voting Ensemble', voting_pred, y_test)
# 앙상블 성능도 좋을 줄 알았는데 나머지 애들을 튜닝을 안 해서 그런지 성능이 10% 안에 진입하지도 못 함!
# voting 앙상블에 대해 정리할 필요가 있다
보팅 (Voting) - 분류 (Classification), regression에서는 hard와 soft 옵션을 못 씀
분류기 모델을 만들때, Voting 앙상블은 1가지의 중요한 parameter가 있습니다.
voting = {'hard', 'soft'}
hard로 설정한 경우
class를 0, 1로 분류 예측을 하는 이진 분류를 예로 들어 보겠습니다.
Hard Voting 방식에서는 결과 값에 대한 다수 class를 차용합니다.
classification을 예로 들어 보자면, 분류를 예측한 값이 1, 0, 0, 1, 1 이었다고 가정한다면 1이 3표, 0이 2표를 받았기 때문에 Hard Voting 방식에서는 1이 최종 값으로 예측을 하게 됩니다.
soft soft vote 방식은 각각의 확률의 평균 값을 계산한다음에 가장 확률이 높은 값으로 확정짓게 됩니다.
가령 class 0이 나올 확률이 (0.4, 0.9, 0.9, 0.4, 0.4)이었고, class 1이 나올 확률이 (0.6, 0.1, 0.1, 0.6, 0.6) 이었다면,
- class 0이 나올 최종 확률은 (0.4+0.9+0.9+0.4+0.4) / 5 = 0.44,
- class 1이 나올 최종 확률은 (0.6+0.1+0.1+0.6+0.6) / 5 = 0.4
가 되기 때문에 앞선 Hard Vote의 결과와는 다른 결과 값이 최종 으로 선출되게 됩니다.
보팅은 분류에서 많이 쓰인다
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression, RidgeClassifier
models = [
('Logi', LogisticRegression()),
('ridge', RidgeClassifier())
]
# voting 옵션에 대하여 지정합니다.
vc = VotingClassifier(models, voting='hard')
배깅(Bagging)
Bagging은 Bootstrap Aggregating의 줄임말입니다. Bag에 feature들이 있고, 이 feature들을 무작위로 뽑아내서 샘플을 만들고, 이것을 결정트리로 만들어 또 다시 무작위 뽑아서 샘플을 만들어서 또 결정트리로 만들어 무작위로 뽑기 때문에 똑같은 특성을 중복해서 뽑는 경우가 생길 가능성 높습니다.
우연의 일치로 또 같은 특성을 뽑았을 때는 비슷한 결정트리가 생길 가능성 높은 것이고, 속도도 느려지고, 하나 만드는 것만 못 한다!
이 중복 추출을 해결하는 방법?
굉장이 많이 만들면 된다( dafault 100개 ) ⇒ Overfitting 생기지 않을까?
feature를 랜덤하게 뽑는데 100개 중 10개만 뽑는다. 이것을 100번 반복하면 100개의 서로 다른 값들의 평균을 구하기 때문에 Overfitting을 방지할 수 있다.
- Bootstrap = Sample(샘플) + Aggregating = 합산
Bootstrap은 여러 개의 dataset을 중첩을 허용하게 하여 샘플링하여 분할하는 방식
데이터 셋의 구성이 [1, 2, 3, 4, 5 ]로 되어 있다면,
- group 1 = [1, 2, 3]
- group 2 = [1, 3, 4]
- group 3 = [2, 3, 5]
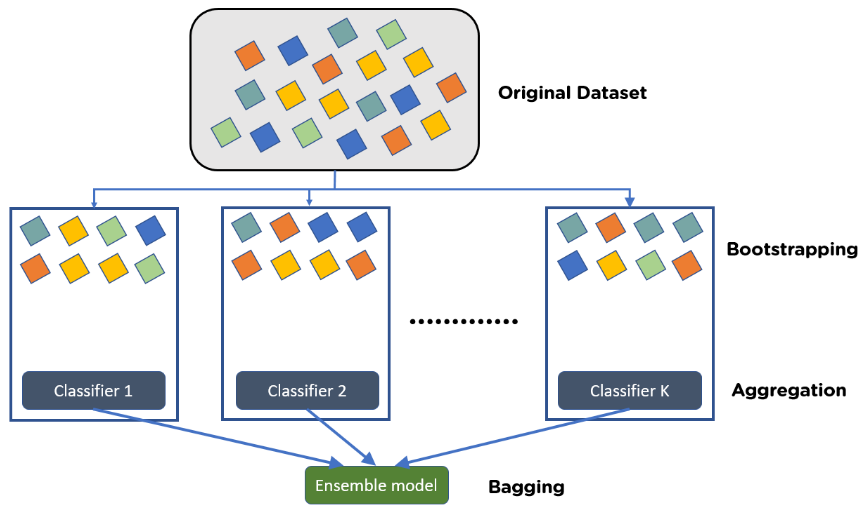
Voting VS Bagging
- Voting은 여러 알고리즘의 조합에 대한 앙상블, 알고리즘(모델)들이 다른 것
- Bagging은 하나의 단일 알고리즘에 대하여 여러 개의 샘플 조합으로 앙상블, 알고리즘(모델)은 같은데 dataset이 다른 것
대표적인 Bagging 앙상블
RandomForest
- Decision Tree기반으로 한 Bagging 기법의 대표적인 알고리즘
- RandomForest is a EnsembleRandomForest is a Bagging
- 가장 인기있는 앙상블 모델중 하나
- 사용법이 쉽고 성능 또한 우수함
장점
- 과대적합이 줄어듦
- 스케일을 맞출 필요가 없음
- 결정 트리 모델의 예측 성능 유지
- 매개변수의 튜닝을 많이 하지 않아도 잘 동작함
단점
- 결정 트리를 많이 만들어야 함
- 대량 데이터 세트라면 다소 시간이 걸릴 수 있음
- 텍스트 데이터 값이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않음
Random Forest 학습 순서
- 생성할 트리 개수를 정하고 Decision Tree를 여러 개 생성
- 각 DT의 노드는 최적이 아닌 랜덤하게 생성
- 부트스트랩 샘플 생성 (n개의 샘플을 무작위로 여러 번 추출)
- 최선의 특성이 아닌 무작위 특성 노드를 선택해서 트리 생성
- 중복되는 데이터로 각 DT 훈련
- 각 DT에게 예측을 시켜서 가장 많이 나온 답을 선택 : Aggregating
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
# 모델 생성
# 결정트리 기본으로 100개 만듦.
rfr = RandomForestRegressor()
# 학습
rfr.fit(x_train, y_train)
# 예측
rfr_pred = rfr.predict(x_test)
mse_eval('RandomForest Ensemble', rfr_pred, y_test)
주요 Hyperparameter
- random_state: 랜덤 시드 고정 값. 고정해두고 튜닝할 것!
- n_jobs: CPU 사용 갯수, -1은 최대로 지정
- max_depth: 깊어질 수 있는 최대 깊이. 과대적합 방지용
- n_estimators: 앙상블하는 트리의 갯수, 기본으로 100개 지정됨
- max_features: 최대로 사용할 feature의 갯수. 과대적합 방지용
- min_samples_split: 트리가 분할할 때 최소 샘플의 갯수. default=2. 과대적합 방지용

rfr.score(x_train, y_train), rfr.score(x_test, y_test) # (0.9795287746282018, 0.8950689109219997)
pred = rfr.predict(x_test)
pred # array([19.42 , 9.852, 19.962, 27.941, ...
튜닝을 할 땐 반드시 random_state 값을 고정시킵니다!
rfr = RandomForestRegressor(random_state=SEED, n_estimators=1000, n_jobs=-1,
max_depth = 7, max_features=0.8)
rfr.fit(x_train, y_train)
rfr_pred = rfr.predict(x_test)
mse_eval('RandomForest Ensemble w/ Tuning', rfr_pred, y_test)

'AI > 머신러닝' 카테고리의 다른 글
| [머신러닝] AutoML 실습 (0) | 2022.04.24 |
|---|---|
| [머신러닝] Ensemble (앙상블) (0) | 2022.04.18 |
| [머신러닝] 결정트리 (0) | 2022.04.18 |
| [머신러닝] 로지스틱 (0) | 2022.04.16 |
| [머신러닝] 회귀 모델 (Regression Models) 2 (0) | 2022.04.16 |




댓글