Google Colab 환경에서 pycaret으로 데이터 분석, 머신러닝 모델 만들기
AutoML이란?
Automated Machine Learning (AutoML)은 기계 학습 파이프 라인에서 수작업과 반족되는 작업을 자동화하는 프로세스이다. AutoML 솔루션은 최근 몇 년간 가장 빠르게 진화하는 기술 중 하나로, 예측 모델 개발에 많은 시간을 소요했던 코딩, 알고리즘 선택, 튜닝 작업을 자동화한다.
코드 한줄, 버튼 클릭 또는 머신러닝 스스로를 통하여 그 동안 복잡했던 수작업, 반복적이었던 작업들은 자동으로 처리해주기 때문에 AutoML을 사용하면 매우 쉽고 효율적으로 원하는 결과값을 얻을 수 있다.
AutoML은 데이터 과학자, 머신러닝 엔지니어 및 연구원의 생산성을 크게 향상시킬 수 있으며, 머신러닝 활용과 접근이 힘들었던 비즈니스 사용자(비전문가)의 접근성과 활용성을 높여준다.
pycaret은 AutoML을 지원하는 파이썬 라이브러리로,
적은 코드로 머신러닝 워크 플로우를 자동화하는 오픈 소스 라이브러리.
머신러닝 모델 개발시 많은 시간을 요구했던 전처리과정, 모델 선택하기, 하이퍼파라미터 튜닝 작업을
자동화해주어 편리하고, 높은 생산성의 작업을 가능하게 한다.
또한, scikit-learn 패키지를 기반으로 하고 있기 때문에
Classification, Regression, Clustering, Anomaly Detection 등등 다양한 모델을 지원한다.
Welcome to PyCaret - PyCaret Official
Compared with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few lines only. This makes experiments exponentially fast and efficient. PyCaret is essentia
pycaret.gitbook.io
1. pycaret Install
!pip install pycaret --quiet
!pip install shap --quiet
2. DataSet Load
- get_data 함수 사용해서 juice 데이터 받아옴
- 함수 실행 결과, 자동으로 head() 실행됨
from pycaret.datasets import get_data
dataset = get_data('juice')
모델의 특성에 맞는 모듈을 import 한다.

우리는 분류 모델을 사용한다.
setup()이라는 강력한 함수로 추후에 필요한 모든 환경, 컬럼값들을 다시 초기화
from pycaret.classification import *
setup_clf = setup(data=dataset, target='Purchase')
3. 모델 생성
create_model()
특정 ML 모델 생성, 모델 학습, 모델 성능까지 한번에 실행하는 기능을 가지고 있다.
create_model() 함수 인자값으로는 분류, 회귀, 군집에 따라서 생성하는 모델의
id 값들이 지정되어져 있으니 공식문서를 참조해서 작성해야 한다.
우리는 분류모델중 성능이 꽤 좋게 나왔던 RandomForest모델을 생성해보자.
Random Forest Classifier는 rf라는 ID를 사용한다.
fold는 데이터셋을 5개로 나누어 cross validation하는 것을 의미합니다.
create_model() 함수는 선언과 동시에 바로 학습하고 결과까지 띄워줍니다.
rf = create_model('rf', fold=5) # 5개로 끊어서 사용하겠다.
4. 모델 성능 비교
compare_models()
위에서 하나의 ML 모델을 생성해서 학습하는 방법을 알아봤다면,
pycaret의 강력한 기능중의 하나인 compare_models() 함수를 이용해서
다양한 모델들의 성능을 비교할 수 있다.
각각 모델들의 성능 정확도를 기준으로
상위 3개의 모델을 top3 에 저장하자.
sort : 모델을 정렬할 평가 지표를 지정
n_select : 상위 몇개의 모델을 선택할지 지정
fold : 교차 검증할 폴드 수를 지정
top3 = compare_models(sort='Accuracy', n_select=3,fold=5)
5. 모델 Tuning
하이퍼파라미터 튜닝하기
tune_model() 함수
그럼 이제 위에서 선택된 5개의 모델을 tuning하자.
pycaret에서 지원하는 tune_model() 함수를 사용.
기본 파라미터로 튜닝할 모델 변수를 입력.
이외에도 다양한 파라미터가 있지만 기본 옵션으로 진행.
tune_model()함수도 실행과 동시에 출력 결과를 보여준다.
기본값으로 fold가 10이므로 10개의 결과와 평균 결과가 출력됨.
튜닝 전에 진행했던 top5와 tuned_top5를 비교해보면 모델 안의 파라미터 값들이
변경된 것을 확인할 수 있다.
tuned_top3 = [tune_model(i) for i in top3]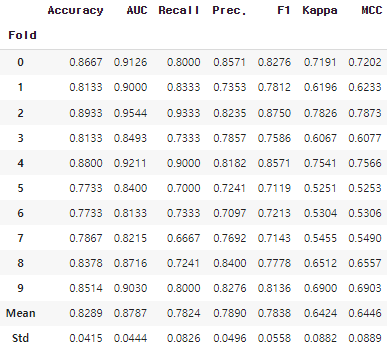
tuned_rf = tune_model(rf, fold=5, optimize='Accuracy')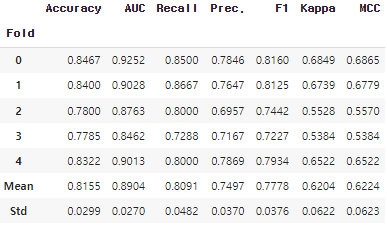
6. 모델 Blending
blend_models(): 이전 단계에서 선택한 모델을 조합하여 더욱 강력한 앙상블 모델을 만듦
- estimator_list : 결합할 모델의 리스트를 지정합니다.
- fold : 교차 검증할 폴드 수를 지정합니다.
- method : 보팅 방식을 지정합니다. (‘soft’ / ‘hard’)
blender_top3 = blend_models(estimator_list=tuned_top3, verbose=True, method='auto') # 기본적으로 10번 학습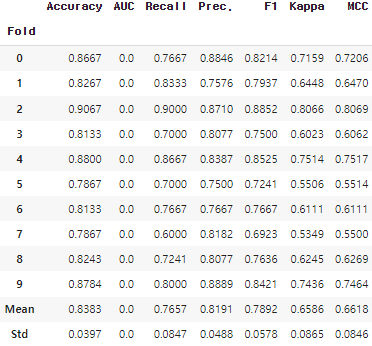
7. 다시 모델 Tuning
- tune_model(): 모델을 튜닝하여 예측 성능을 올립니다.
blender_tune3 = tune_model(blender_top3)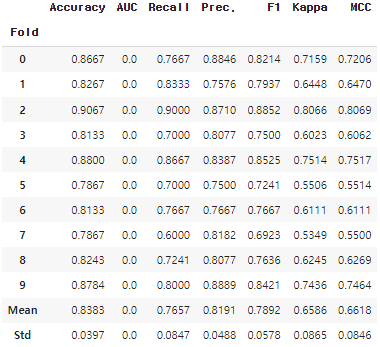
8. 모델 예측하기
학습한 최종 모델로 Prediction 하는 방법을 알아보겠습니다. 우선 지금까지는 setup에 넣었던 데이터가 KFold 방식으로 train/valid 로 나누어 학습했었습니다. finalize_model()함수를 통해 전체 데이터로 마지막 학습을 진행합니다.
이후에 predict_mdodel() 함수의 파라미터로 학습된 모델 변수, 테스트할 pandas dataframe을 각각 입력해주면 됩니다. 아래 코드에서는 테스트 데이터로 dataset의 마지막 100개의 데이터를 사용하겠습니다.
아래는 prediction 의 출력입니다. prediction은 test data의 데이터 프레임 형태를 그대로 가져가며 마지막에에 Label 이라는 column이 생기고, 여기에 모델이 예측한 결과가 추가됩니다.
학습에서 사용했던 데이터, 검증에서 사용했던 데이터 나눠 학습하지 않고, 한꺼번에 학습하고 final 모델로 마지막으로 예측하는 모델로 넣는다.
final_model = finalize_model(blender_tune3)
prediction = predict_model(final_model, data=dataset)
prediction
prediction = prediction['Label']
prediction
'''
0 CH
1 CH
2 CH
3 MM
4 CH
..
1065 CH
1066 CH
1067 CH
1068 CH
1069 CH
Name: Label, Length: 1070, dtype: object
'''
8. Evaluation
마지막으로 모델을 평가할 차례입니다. check_metric을 import 해주고, gt와 prediction을 각각 입력하고, 확인하고 싶은 metric을 입력해주면 결과값이 출력됩니다.
from pycaret.utils import check_metric
check_metric(dataset['Purchase'], prediction, metric = 'Accuracy') # 0.8393
9. 전체 코드 Flow
- pip install pycaret
- Library : 사용할 패키지를 불러옵니다.
- Load Dataset
- Setup Environment
- Compare Models . 중요
- Create Models . 중요
- Tune Models . 중요
- Predict
- Evaluation
'AI > 머신러닝' 카테고리의 다른 글
| [머신러닝] Ensemble (앙상블) (0) | 2022.04.18 |
|---|---|
| [머신러닝] Ensemble (앙상블) (0) | 2022.04.18 |
| [머신러닝] 결정트리 (0) | 2022.04.18 |
| [머신러닝] 로지스틱 (0) | 2022.04.16 |
| [머신러닝] 회귀 모델 (Regression Models) 2 (0) | 2022.04.16 |




댓글