부스팅 (Boosting)
대표적인 Boosting 앙상블
- AdaBoost , 제일 오래된 알고리즘, 잘 안 쓰임..
- GradientBoost
- LightGBM (LGBM) (MS사 라이브러리, install 필요)
- XGBoost (외부 라이브러리, install 필요)
성능이 좋은 건? XGBoost업계에서 조금 더 많이 쓰는 것? LightGBM,
XGBoost가 성능이 조금 더 좋은데 왜 업계에서는 LightGBM 쓸까? XGBoost 속도가 너무 느려! MS에서는 LightGBM으로 문제점을 보완하고 어느정도 성능도 보장해줌!

Boosting 알고리즘 역시 앙상블 학습 (ensemble learning)이며, 약한 학습기를 순차적으로 학습을 하되, 이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완해 나가는 방식입니다.
다른 앙상블 기법과 가장 다른 점중 하나는 바로 순차적인 학습을 하며 weight를 부여해서 오차를 보완해 나간다는 점인데요.순차적이기 때문에 병렬 처리에 어려움이 있고, 그렇기 때문에 다른 앙상블 대비 학습 시간이 오래걸린다는 단점이 있습니다.
약한 학습기를 순차적으로 학습을 하되, 이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완해 나가는 방식입니다.
장점
- 성능이 매우 우수하다 (SGBoost, ADBoost, Lgbm, XGBoost)
- ADBoost는 다소 이전에 만들어 졌기에 여기서는 별도로 언급하지 않겠다.
- Lgbm 은 마이크로스프트에서 만든 모델
- XGBoost는 오픈소스
- SGBoost모델은 사이킷런에서 제공
단점
- 부스팅 알고리즘의 특성상 계속 약점(오분류/잔차)을 보완하려고 하기 때문에 잘못된 레이블링이나 아웃라이어에 필요 이상으로 민감할 수 있다
- 다른 앙상블 대비 학습 시간이 오래걸린다는 단점이 존재
GradientBoost
- 성능이 우수함
- 학습시간이 해도해도 너무 느리다
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor
gbr = GradientBoostingRegressor(random_state=SEED)
gbr.fit(x_train, y_train)
gbr_pred = gbr.predict(x_test)
mse_eval('GradientBoost Ensemble', gbr_pred, y_test)
주요 Hyperparameter
- random_state: 랜덤 시드 고정 값. 고정해두고 튜닝할 것!
- n_jobs: CPU 사용 갯수
- learning_rate: 학습율. 너무 큰 학습율은 성능을 떨어뜨리고, 너무 작은 학습율은 학습이 느리다. 적절한 값을 찾아야함. n_estimators와 같이 튜닝. default=0.1
- n_estimators: 부스팅 스테이지 수. (랜덤포레스트 트리의 갯수 설정과 비슷한 개념). default=100
- subsample: 샘플 사용 비율 (max_features와 비슷한 개념). 과대적합 방지용
- min_samples_split: 노드 분할시 최소 샘플의 갯수. default=2. 과대적합 방지용
gbr = GradientBoostingRegressor(random_state=SEED, learning_rate=0.01)
gbr.fit(x_train, y_train)
gbr_pred = gbr.predict(x_test)
mse_eval('GradientBoosting(lr=0.01)', gbr_pred, y_test)
# learning rate가 너무 작아서 학습이 다 되기도 전에 끝나버림!
# 위에서는 n_estimators가 defualt 100이었고, learning_rate가 0.1이였으니까 learning_rate를 1/10로 줄여서 n_estimators를 10배 늘려서 1000으로 넣음
gbr = GradientBoostingRegressor(random_state=SEED, learning_rate=0.01, n_estimators=1000)
gbr.fit(x_train, y_train)
gbr_pred = gbr.predict(x_test)
mse_eval('GradientBoosting(lr=0.01, est=1000)', gbr_pred, y_test)
gbr = GradientBoostingRegressor(random_state=SEED, learning_rate=0.01, n_estimators=1000, subsample=0.8)
gbr.fit(x_train, y_train)
gbr_pred = gbr.predict(x_test)
mse_eval('GradientBoosting(lr=0.01, est=1000, subsample=0.8)', gbr_pred, y_test)

XGBoost
eXtreme Gradient Boosting
주요 특징
- scikit-learn 패키지가 아닙니다.
- Structured Data(정형 데이터)를 가지고 예측할 때 성능이 우수한 알고리즘으로 주목받습니다.
- Regression 또는 Classification 같은 예측 분석에 사용됩니다.
- GBM보다는 빠르고 성능도 향상되었습니다.
- 여전히 학습시간이 매우 느리지만 GPU지원을 하기 때문에 GPU 사용해서 학습을 하면 속도가 빨라질 수 있습니다.
- 외부 패키지이지만 사용법은 이전과 동일합니다.
from xgboost import XGBClassifier, XGBRegressor
xgb = XGBRegressor(random_state=SEED)
xgb.fit(x_train, y_train)
xgb_pred = xgb.predict(x_test)
mse_eval('XGBoost', xgb_pred, y_test)
print(xgb.score(x_train, y_train), xgb.score(x_test, y_test))
위에꺼 바로 튜닝
xgb = XGBRegressor(random_state=SEED, learning_rate=0.01, n_estimators=1000,subsample=0.7, max_teatures=0.7)
xgb.fit(x_train, y_train)
xgb_pred = xgb.predict(x_test)
mse_eval('XGBoost w/Tuning', xgb_pred, y_test)

LightGBM
주요 특징
- scikit-learn 패키지가 아닙니다 (Microsoft 사 개발)
- Gradient Boosting Tree 기반 학습 알고리즘 입니다.
- 속도가 빠르기 때문에 많이 사용되며 큰 사이즈의 데이터를 다룰 수 있고 실행시킬 때 적은 메모리를 차지합니다.
- 과대 적합에 민감하고 작은 데이터에 대해서 과대 적합하기 쉬운 모델로 데이터 개수에 대한 제한은 없지만 10,000개 이상의 행을 가진 데이터에 사용하는 것을 권유합니다.
특이점
- 기존 부스팅 계열 알고리즘이 가지는 단점인 느린 학습 속도를 개선하였습니다.
from lightgbm import LGBMClassifier, LGBMRegressor
lgbm = LGBMRegressor(random_state=SEED)
lgbm.fit(x_train, y_train)
lgbm_pred = lgbm.predict(x_test)
mse_eval('LGBM', lgbm_pred, y_test)
위에꺼 튜닝
lgbm = LGBMRegressor(random_state=SEED, learning_rate=0.01, n_estimators=200,
subsample=0.7, max_teatures=0.7)
lgbm.fit(x_train, y_train)
lgbm_pred = lgbm.predict(x_test)
mse_eval('LGBM /w Tuning', lgbm_pred, y_test)
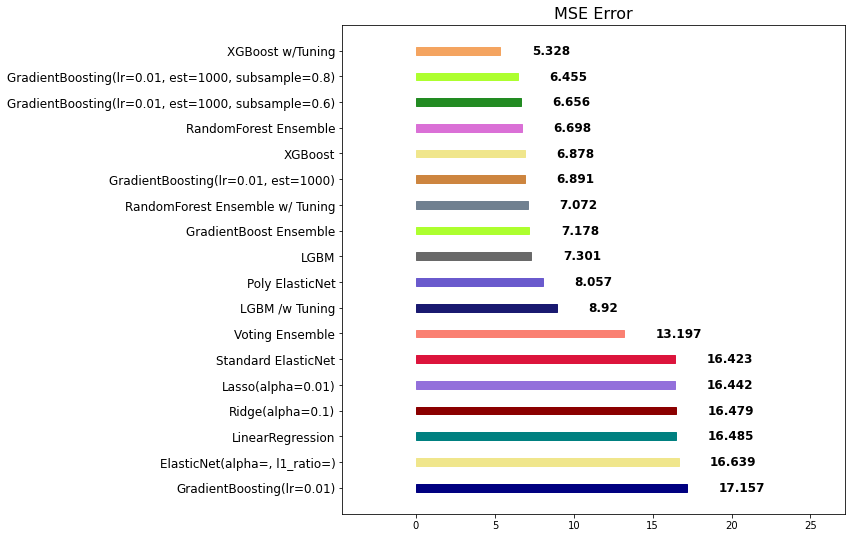
Stacking
여러 모델이 예측한 결과 값을 다른 모델의 학습 데이터로 입력하여 재학습합니다.
개별 모델이 예측한 데이터를 기반으로 final_estimator 종합하여 예측을 수행합니다.
ex) XGBoost가 하나 더 있는 것과 같음
- 성능을 극으로 끌어올릴 때 활용하기도 합니다.
- 성능향상 보장하지 못 함. 과대적합을 유발할 수 있습니다. (특히, 데이터셋이 적은 경우)
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import Lasso
stack_models = [
('randomforest', rfr),
('gbr', gbr),
('lgbm', lgbm),
]
stack_reg = StackingRegressor(stack_models, final_estimator=xgb, n_jobs=-1)
stack_reg.fit(x_train, y_train)
stack_pred = stack_reg.predict(x_test)
mse_eval('Stacking Ensemble', stack_pred, y_test)
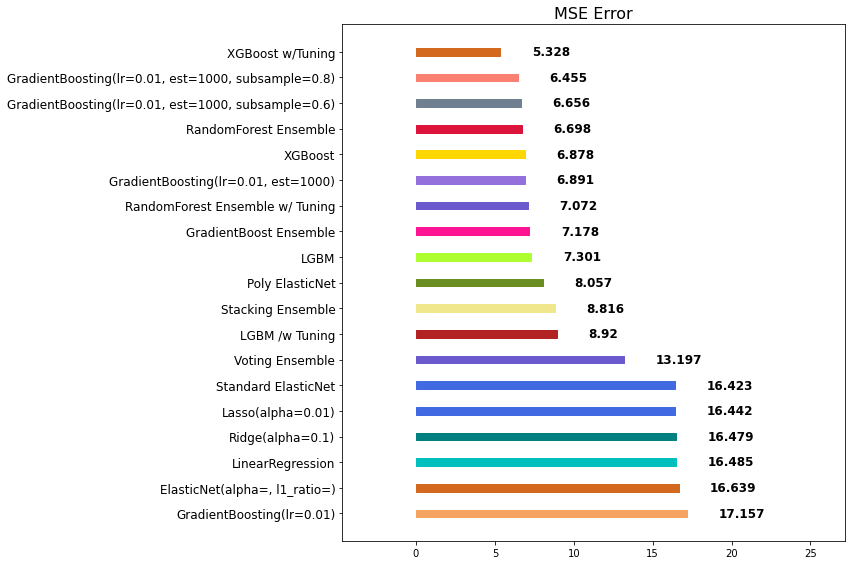
Weighted Blending ⇒ 앙상블의 앙상블
각 모델의 예측값에 대하여 weight를 곱하여 최종 output 계산
- 각각 나온 예측 결과에 대한 동일한 평균을 내는 방식이 아니라
- 모델에 대한 가중치를 조절하여, 최종 output을 산출합니다.
- 가중치의 합은 1.0이 되도록 합니다.
final_outputs = {
'elasticnet': poly_pred,
'randomforest': rfr_pred,
'gbr': gbr_pred,
'xgb': xgb_pred,
'lgbm': lgbm_pred,
'stacking': stack_pred,
}
final_prediction=\\
final_outputs['elasticnet'] * 0.1\\
+final_outputs['randomforest'] * 0.2\\
+final_outputs['gbr'] * 0.2\\
+final_outputs['xgb'] * 0.25\\
+final_outputs['lgbm'] * 0.15\\
+final_outputs['stacking'] * 0.1
# 보통은 weighted blending이 1등으로 넘어선다!
mse_eval('Weighted Blending', final_prediction, y_test)
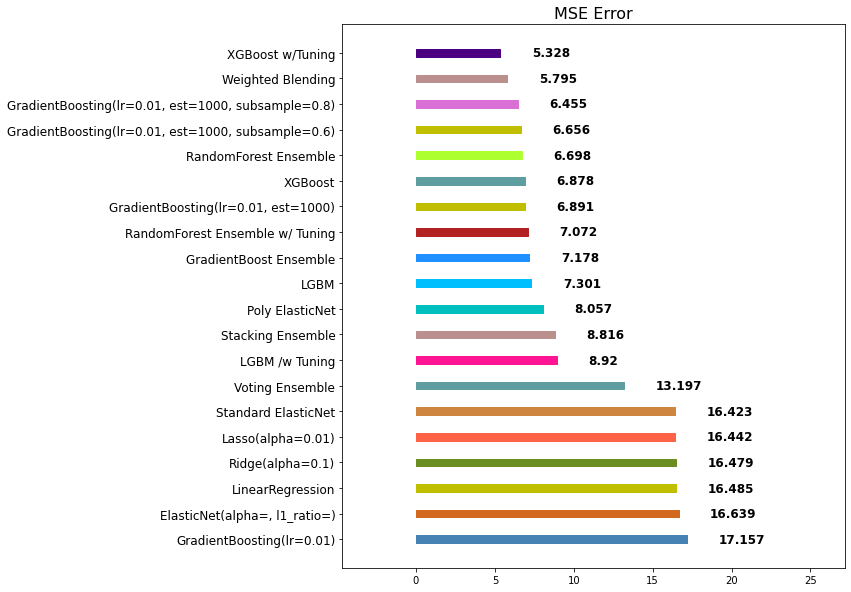
앙상블 모델을 정리하며
- 앙상블은 대체적으로 단일 모델 대비 성능이 좋습니다.
- 앙상블을 앙상블하는 기법인 Stacking과 Weighted Blending도 참고해 볼만 합니다.
- 앙상블 모델은 적절한 Hyperparameter 튜닝이 중요합니다.
- 앙상블 모델은 대체적으로 학습시간이 더 오래 걸립니다.
- 따라서, 모델 튜닝을 하는 데에 걸리는 시간이 오래 소요됩니다.
- xgb와 lgbm은 모두 부스팅 계열이라 같은 계열을 앙상블로 묶으면 효과 없음
- xgb 부스팅 기법과 rfr(랜덤포레스트) 배깅 기법이 합쳐지면 최적이 됨!
- 따라서 적절한 Hyperparameter 튜닝 후 완전히 다른 알고리즘으로 앙상블 진행하기!
- 마지막으로 weighted blending으로 최종 보루로 사용하면 최고!
검증 (Validation)과 튜닝 (Tuning)
Cross Validation
- Cross Validation이란 모델을 평가하는 하나의 방법입니다.
- K-겹 교차검증(K-fold Cross Validation)을 많이 활용합니다.
- 고정적인 학습 데이터 세트로 모델을 만드는 경우 과대적합이 발생할 수 있습니다. 따라서 새로운 데이터에 대해서도 충분한 정확도를 확보하기 위해서는 과대적합을 제어할 수 있어야 합니다.
장점
- 교차 검증을 통해 모든 데이터를 학습에 활용함으로써 정확도를 향상시킬 수 있으며 데이터 부족으로 인한 과소적합을 방지할 수 있습니다.
- 교차 검증을 통해 모든 데이터를 평가에 활용함으로써 특정 데이터에 과대적합 되는 것을 방지하여 일반화된 모델을 만들 수 있습니다.
K-겹 교차검증
- 데이터를 동일한 개수인 K개의 Fold로 분할
- K번 학습을 진행하며 매 학습마다 사용되는 Fold를 변경하면서 학습 및 평가
- 모든 데이터를 학습과 평가에 쓸 수 있고 과대적합의 염려도 크지 않지만 시간이 다소 오래 걸린다는 단점이 존재
- K-겹 교차 검증은 모든 데이터가 최소 한 번은 테스트셋으로 쓰이도록 합니다. 아래의 그림을 보면, 데이터를 5개로 쪼개 매번 테스트셋을 바꿔나가는 것을 볼 수 있습니다.
[예시]
- Estimation 1일때,
학습데이터: [B, C, D, E] / 검증데이터: [A]
- Estimation 2일때,
학습데이터: [A, C, D, E] / 검증데이터: [B]
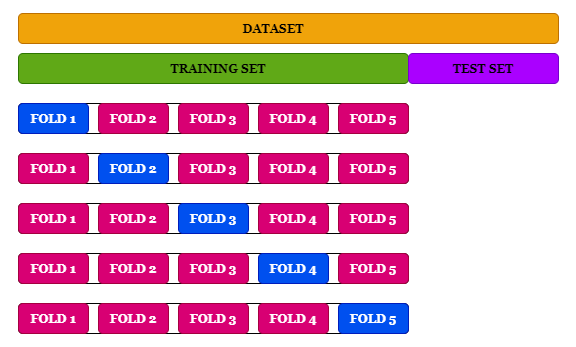
K-Fold Cross Validation
from sklearn.model_selection import KFold
n_splits = 5
# kfold = KFold(n_splits=5, random_state=40)
kfold = KFold(n_splits=5)
X = np.array(df.drop('target', 1))
Y = np.array(df['target'])
lgbm_fold = LGBMRegressor(random_state=30)
i = 1
total_error = 0
for train_index, test_index in kfold.split(X):
x_train_fold, x_valid_fold = X[train_index], X[test_index]
y_train_fold, y_valid_fold = Y[train_index], Y[test_index]
lgbm_pred_fold = lgbm_fold.fit(x_train_fold, y_train_fold).predict(x_valid_fold)
error = mean_squared_error(lgbm_pred_fold, y_valid_fold)
print('Fold = {}, prediction score = {:.2f}'.format(i, error))
total_error += error
i+=1
print('---'*10)
print('Average Error: %s' % (total_error / n_splits))
Hyperparameter 튜닝
- hypterparameter 튜닝시 경우의 수가 너무 많습니다.
- 따라서, 우리는 자동화할 필요가 있습니다.
sklearn 패키지에서 자주 사용되는 hyperparameter 튜닝을 돕는 클래스는 다음 2가지가 있습니다.
- RandomizedSearchCV
- GridSearchCV
적용하는 방법
- 사용할 Search 방법을 선택합니다.
- hyperparameter 도메인을 설정합니다. (max_depth, n_estimators..등등)
- 학습을 시킨 후, 기다립니다.
- 도출된 결과 값을 모델에 적용하고 성능을 비교합니다.
RandomizedSearchCV
- 모든 매개 변수 값이 시도되는 것이 아니라 지정된 분포에서 고정 된 수의 매개 변수 설정이 샘플링됩니다.
- 시도 된 매개 변수 설정의 수는 n_iter에 의해 제공됩니다.
주요 Hyperparameter (LGBM)
- random_state: 랜덤 시드 고정 값. 고정해두고 튜닝할 것!
- n_jobs: CPU 사용 갯수
- learning_rate: 학습율. 너무 큰 학습율은 성능을 떨어뜨리고, 너무 작은 학습율은 학습이 느리다. 적절한 값을 찾아야함. n_estimators와 같이 튜닝. default=0.1
- n_estimators: 부스팅 스테이지 수. (랜덤포레스트 트리의 갯수 설정과 비슷한 개념). default=100
- max_depth: 트리의 깊이. 과대적합 방지용. default=3.
- colsample_bytree: 샘플 사용 비율 (max_features와 비슷한 개념). 과대적합 방지용. default=1.0
n_iter 값을 조절하여, 총 몇 회의 시도를 진행할 것인지 정의합니다.
(회수가 늘어나면, 더 좋은 parameter를 찾을 확률은 올라가지만, 그만큼 시간이 오래걸립니다.)
params = {
'n_estimators': [200, 500, 1000, 2000],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [6, 7, 8],
'colsample_bytree': [0.7, 0.8, 0.9],
'subsample': [0.8, 0.9,],
}
from sklearn.model_selection import RandomizedSearchCV
clf = RandomizedSearchCV(LGBMRegressor(), params,
random_state=SEED, cv=5 , n_iter=30,scoring='neg_mean_squared_error')
clf.fit(x_train, y_train)
abs(clf.best_score_) # 12.602959720760321
clf.best_params_
'''
{'subsample': 0.8,
'n_estimators': 1000,
'max_depth': 7,
'learning_rate': 0.05,
'colsample_bytree': 0.7}
'''
lgbm_best = LGBMRegressor(**clf.best_params_)
lgbm_best.fit(x_train, y_train)
lgbm_best_pred = lgbm_best.predictdict(x_test)
mse_eval('RandomSearch LGBM', lgbm_best_pred, y_test)
GridSearchCV
- 모든 매개 변수 값에 대하여 완전 탐색을 시도합니다.
- 따라서, 최적화할 parameter가 많다면, 시간이 매우 오래걸립니다.
- 완전탐색(모든 조합을 다 돌린다)을 하기 때문에 최고의 점수를 내는 조합을 찾습니다.
params = {
'n_estimators': [500, 1000],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [7, 8],
'colsample_bytree': [0.8, 0.9],
'subsample': [0.8, 0.9,],
}
from sklearn.model_selection import GridSearchCV
'AI > 머신러닝' 카테고리의 다른 글
| [머신러닝] AutoML 실습 (0) | 2022.04.24 |
|---|---|
| [머신러닝] Ensemble (앙상블) (0) | 2022.04.18 |
| [머신러닝] 결정트리 (0) | 2022.04.18 |
| [머신러닝] 로지스틱 (0) | 2022.04.16 |
| [머신러닝] 회귀 모델 (Regression Models) 2 (0) | 2022.04.16 |




댓글